Variabele instellingen, Weergavegroepen & Forecastconfiguraties.
 Updated
by
Daniel Sjögren
Updated
by
Daniel Sjögren
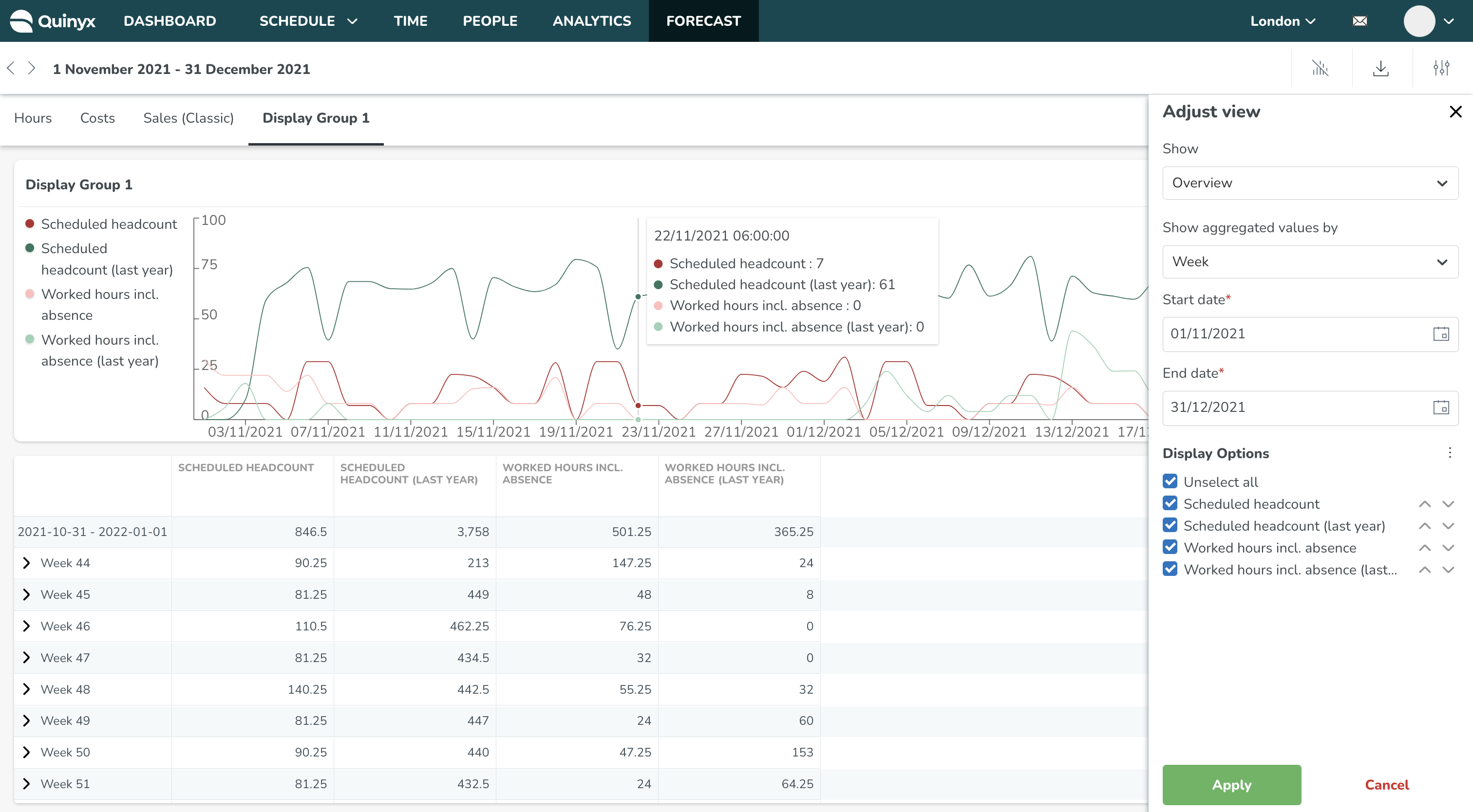
Op de pagina met variabele instellingen kunt u uw forecastconfiguraties en variabele weergaveopties maken en beheren, inclusief het toevoegen ervan aan weergavegroepen. Weergavegroepen beïnvloeden hoe variabelen worden weergegeven in de planningstatistieken en het Forecast-tabblad.
Navigeren naar Optimalisatie-instellingen > Variabelen > Variabele instellingen geeft een overzicht van al uw configuraties, berekende en standaardvariabelen, en waar ze momenteel worden weergegeven.
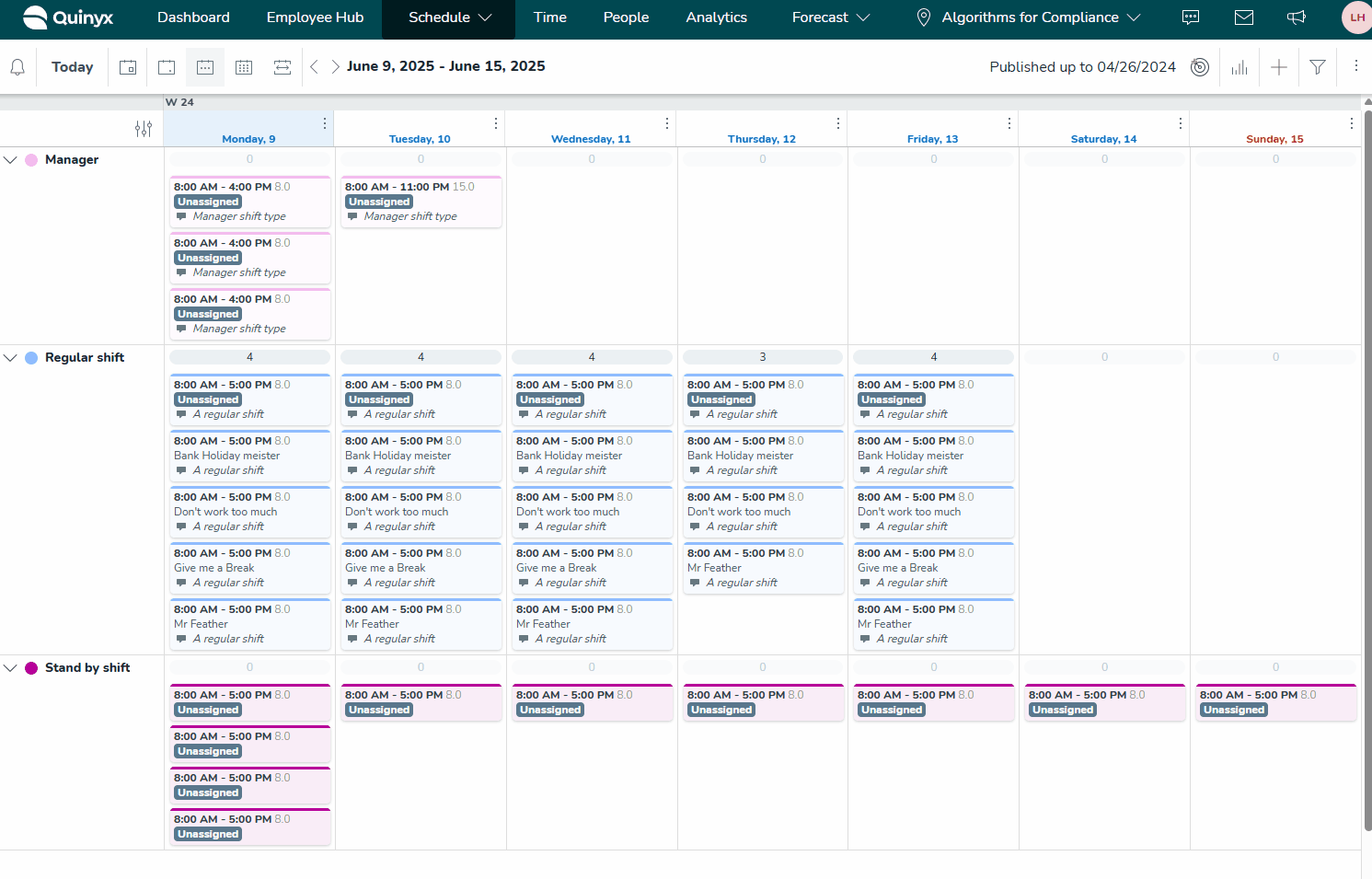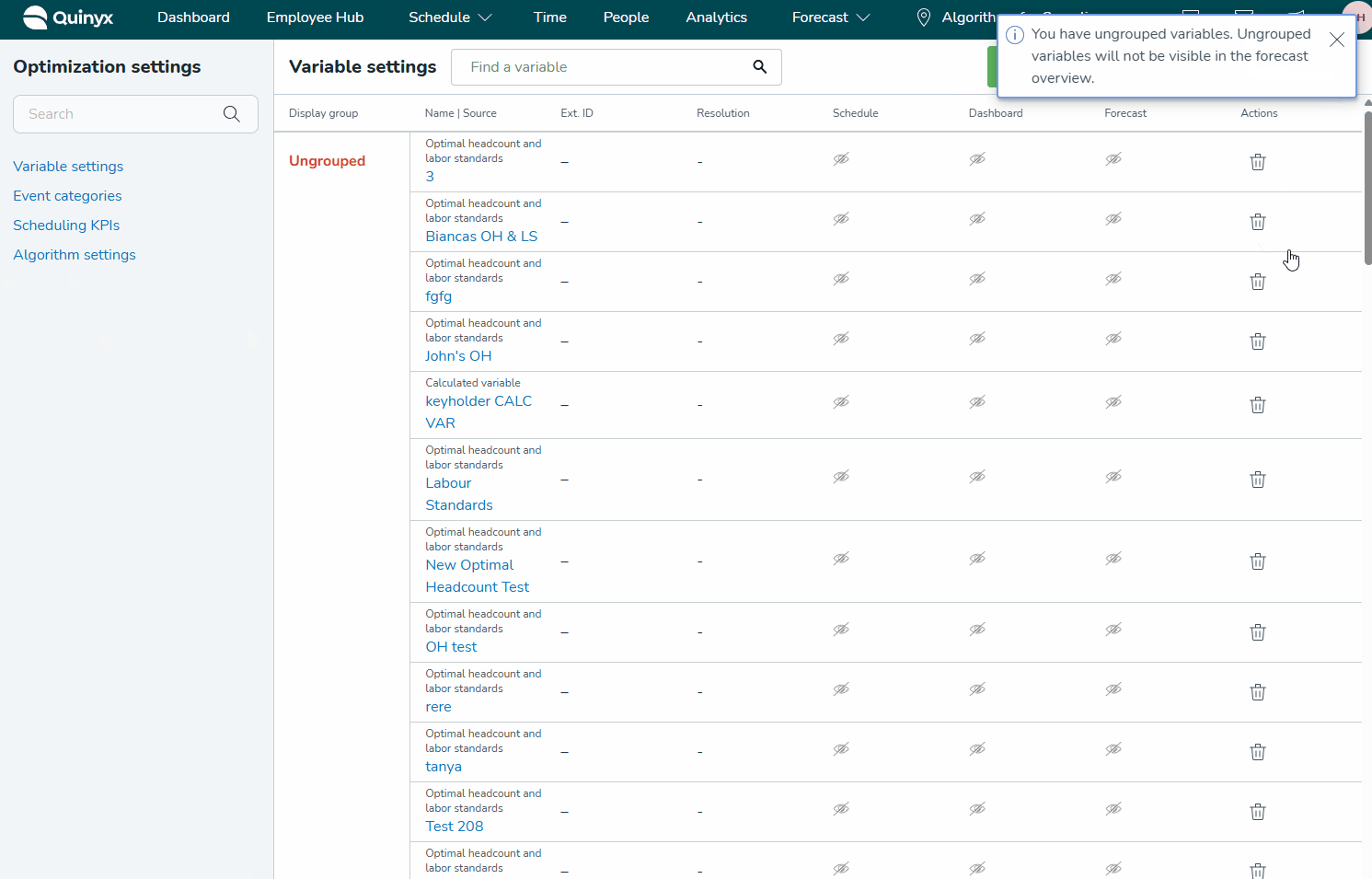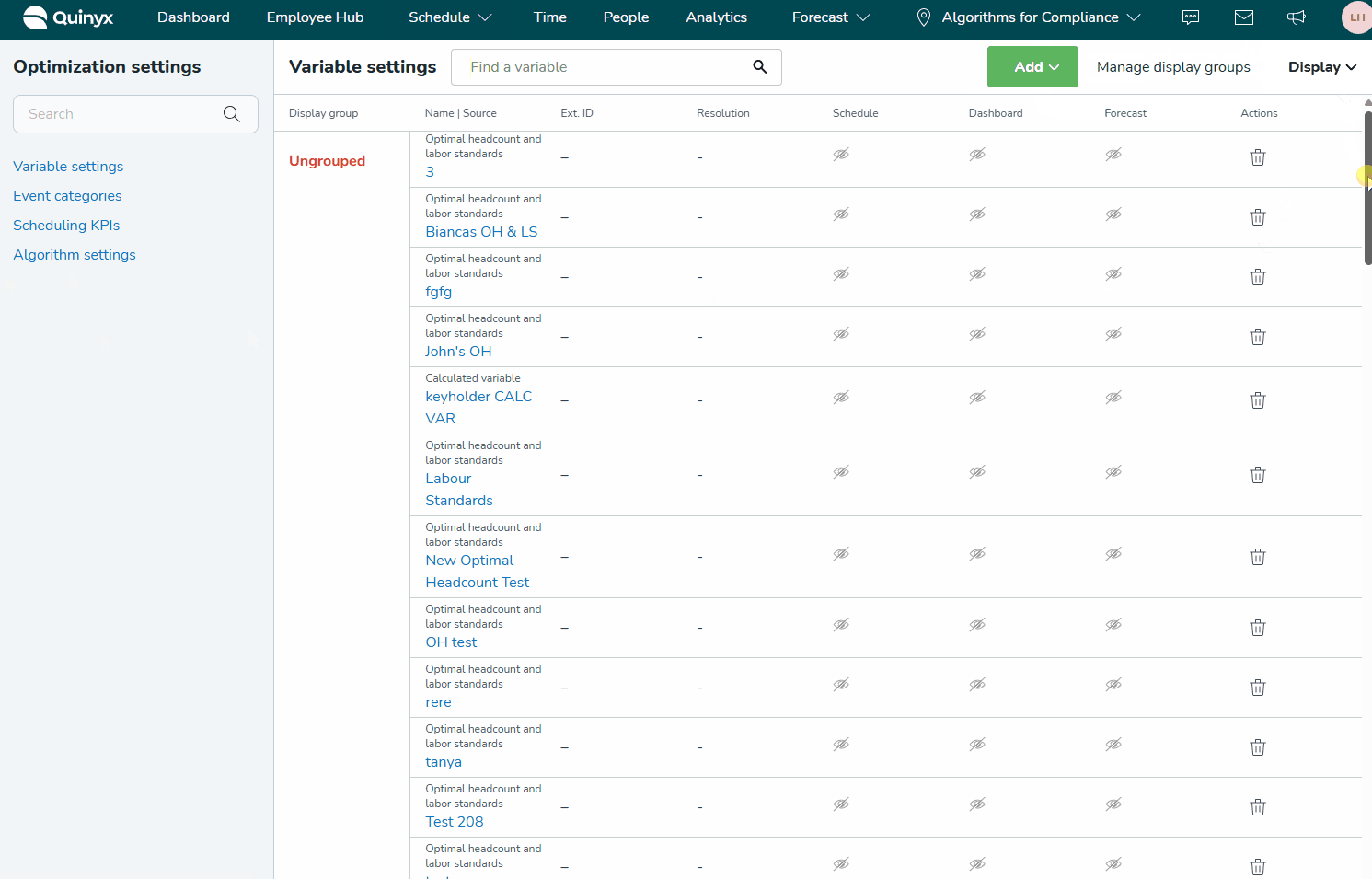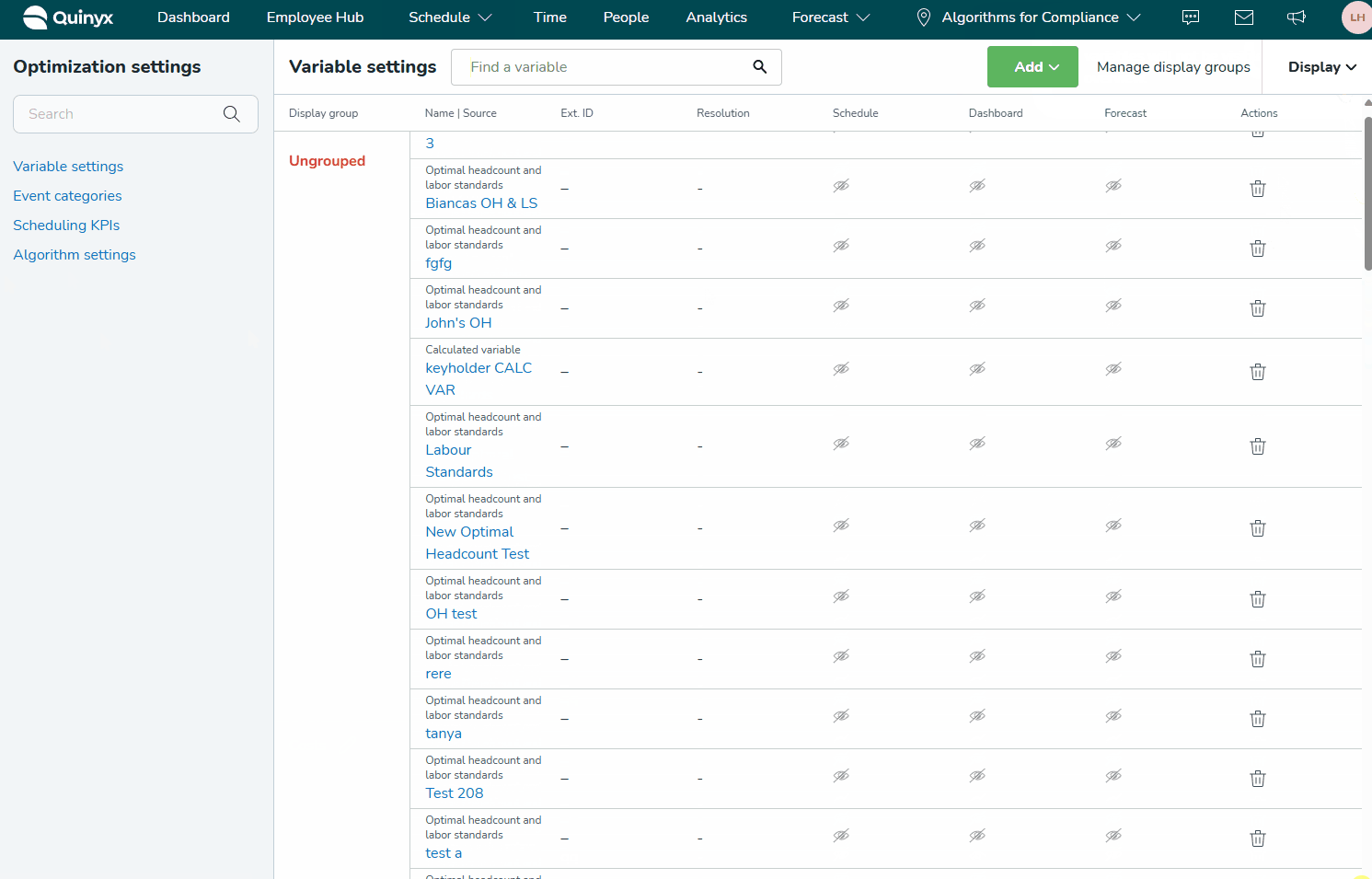
Als u al variabelen hebt gemaakt en een bestaande wilt bewerken, begint u de naam in het zoekvak te typen. Alle variabele instellingen die die letters bevatten, worden weergegeven.
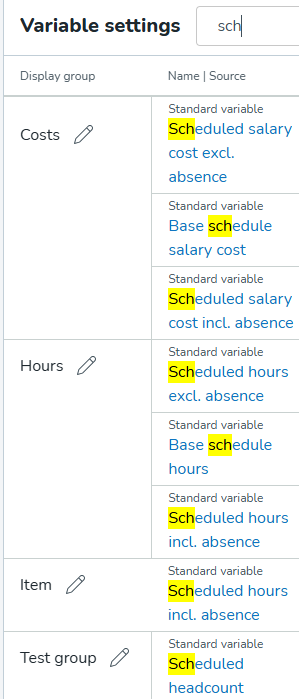
U kunt niet alleen filteren op variabele naam, maar ook op type variabele (bijv. het typen van "optima" zal alle optimale personeelbezetting-variabelen en variabelen met namen die "optima" bevatten, retourneren).
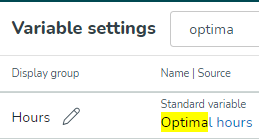
Door op de knop Toevoegen bovenaan de pagina te klikken, krijgt u opties om nieuwe Input Data, Forecast Configuration, Calculated Variable of Optimal Headcount-berekening toe te voegen.
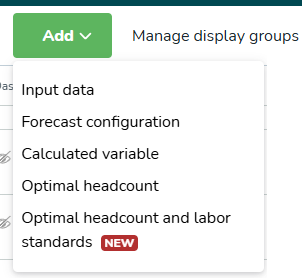
Input data | Externe data die via de API naar Quinyx worden verzonden. Vereist om een prognose te genereren. |
Forecast configuration | Een configuratieset om te bepalen hoe een prognose wordt gegenereerd. Dit moet worden gekoppeld aan Input Data. Quinyx gebruikt historische input data om te helpen bij het genereren van een voorspelling voor de toekomst. |
Calculated variable | Een variabele die wordt gegenereerd op basis van berekeningen uitgevoerd tussen 2 of meer variabelen. |
Optimal headcount | Gebruikt om een optimale personeelbezetting-berekening te genereren op basis van statisch en dynamische regels |
Optimale personeelbezetting en arbeidsnormen | Gebruikt om u te helpen het optimale aantal medewerkers te bepalen dat nodig is om aan de voorspelde vraag te voldoen. Lees meer "hier". |
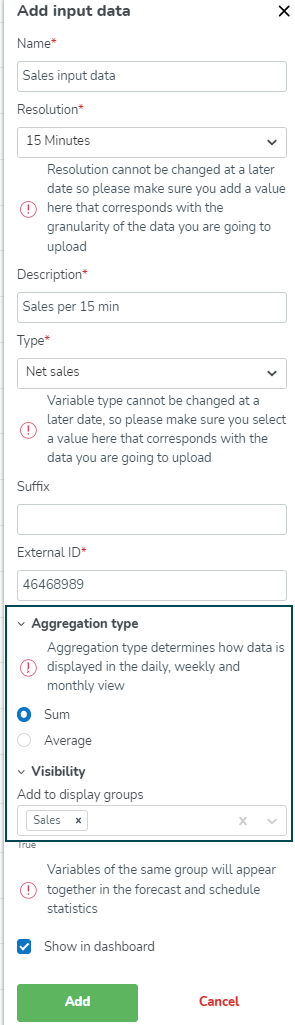
Invoergegevens
Forecast invoergegevens zijn wat de personeelsbehoeften aandrijft. Deze gegevens worden vanuit een extern systeem naar Quinyx gestuurd.
Het selecteren van het toevoegen van invoergegevens zal het zijpaneel tonen dat de volgende informatie vereist.
Naam | Dit is de naam van de invoergegevens, bijvoorbeeld de driver die u wilt gebruiken. Bijvoorbeeld. Netto-omzet incl. BTW als dat de gegevens zijn die u wilt gebruiken in verband met deze driver. |
Resolutie (minuutniveau) | 5 / 15 / 30 / 60 Minuten: Deze opties stellen u in staat om met meer gedetailleerde gegevens te werken. Bijvoorbeeld, het kiezen van 15 Minuten betekent dat alle tijdgerelateerde gegevens (zoals personeelsvraag of dienstdekking) gegroepeerd en getoond worden in intervallen van 15 minuten. Resolutie kan later niet meer worden gewijzigd, dus zorg ervoor dat u hier een waarde toevoegt die overeenkomt met de granulariteit van de gegevens die u gaat uploaden |
Resolutie (dagelijks niveau) | Naast bestaande resoluties (5, 15, 30 en 60 minuten), kunnen gebruikers gegevens importeren en ermee werken op een dagelijks niveau Met een dagelijkse resolutie kunt u:
U kunt dagelijkse gegevens direct bewerken binnen het Forecast-tabblad en de Statistieken-weergave. De dagelijkse optie vat alle gegevens samen tot één waarde per dag. Het is het beste te gebruiken wanneer gedetailleerde uur-tot-uur inzichten niet nodig zijn—handig voor hoog-niveau planning of rapportage. Belangrijke verschillen bij het bewerken van dagelijkse gegevens Vergeleken met het bewerken van gegevens met een resolutie van 60 minuten of minder, heeft het bewerken van dagelijkse gegevens de volgende beperkingen:
|
Beschrijving | Dit is de beschrijving van de invoergegevens om deze gemakkelijk te kunnen identificeren in de lijst met invoergegevens als u meerdere invoergegevens heeft. |
Type | Dit is het type invoervariabele en voor configuratie- en statistisch gebruik in analyses moet het juiste type worden gebruikt dat overeenkomt met uw driver. Bijvoorbeeld, Netto-omzet incl. BTW moet worden gekoppeld aan Netto-omzet, terwijl Bruto-omzet incl. TIP moet worden gekoppeld aan Bruto-omzet. Het type variabele kan later niet meer worden gewijzigd, dus zorg ervoor dat u hier een waarde selecteert die overeenkomt met de gegevens die u gaat uploaden |
Achtervoegsel | Momenteel niet gebruikt, maar zal in toekomstige weergaven valuta of iets dergelijks weergeven. |
Externe ID | Dit is de Externe ID voor de invoergegevens. Dit is een van de items die een integrator nodig zou hebben om de juiste gegevens naar de juiste invoergegevens in Quinyx te uploaden. Bijvoorbeeld, in het datawarehouse voor het POS-systeem (point of sales) is het corresponderende nummer voor Netto-omzet incl. BTW. |
Aggregatietype | Aggregatietype bepaalt hoe gegevens worden weergegeven in de dagelijkse, wekelijkse en maandelijkse weergave. Kies Som of Gemiddelde. |
Zichtbaarheid | Dit bepaalt in welke weergavegroep(en) de invoergegevens worden weergegeven. Voor de standaardvariabelen die automatisch worden toegevoegd aan standaardweergavegroepen, zoals Kosten en Uren, evenals de Optimal Headcount-variabelen die worden toegevoegd aan de standaardweergavegroep Arbeid, heeft Quinyx een kleine maar significante componentindicator in de Zichtbaarheid invoer die die standaardweergavegroepen vertegenwoordigt. Dit helpt gebruikers door informatie te geven over of een variabele al deel uitmaakt van een standaardweergavegroep. 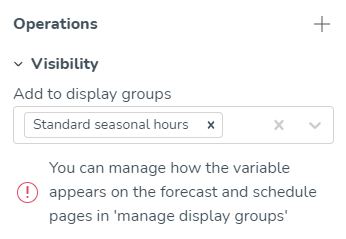 |
Weergeven in dashboard | Bepaal of dit zichtbaar moet zijn in de dashboardweergave. Variabelen met salaris kostencalculaties worden niet weergegeven in het dashboard. |
ForecastConfiguratie
Zodra u Invoergegevens hebt aangemaakt, kunt u een configuratie maken voor hoe toekomstige gegevens moeten worden geprognosticeerd.
U kunt dit doen door Forecast Configuration te selecteren via de Toevoegen-knop bovenaan de pagina.
Het selecteren van Forecast Configuration toevoegen zal het zijpaneel openen dat de volgende informatie vereist.
Naam | Dit is de naam van de forecast en hoe deze zal worden genoemd in planning views en andere relevante views. |
Beschrijving | Een beschrijving van deze configuratie om deze gemakkelijk te kunnen identificeren als er veel configuraties zijn gemaakt. |
Externe ID | Een ID voor verwijzing naar deze specifieke forecast configuratie bij gebruik van de API. |
Invoergegevens | Hier kiest u welke invoergegevens moeten worden gebruikt. U kunt meerdere configuraties hebben voor dezelfde invoergegevens. |
Forecast formule/Data algoritmen | Hier definieert u welke algoritmen u wilt gebruiken. Momenteel bestaan de volgende:
Quinyx genereert automatisch een prognose voor 90 dagen vooruit, zolang er ten minste 60 dagen aan historische gegevens beschikbaar zijn. Lees meer hier. |
Aggregatietype | Het aggregatietype bepaalt hoe gegevens worden weergegeven in de dagelijkse, wekelijkse en maandelijkse weergave. Kies Som of Gemiddelde. |
Zichtbaarheid | Bepaalt in welke weergavegroepen de invoergegevens worden weergegeven. U kunt beheren hoe de variabele verschijnt op de forecast- en planningspagina's in Beheer weergavegroepen. |
Dashboard | Selecteer of dit zichtbaar moet zijn in de dashboardweergave. |
Berekende variabelen
Een berekende variabele wordt afgeleid door een berekening uit te voeren met twee andere variabelen—dit kunnen standaardvariabelen, invoergegevens of een mix van beide zijn.
Wanneer u ervoor kiest om een berekende variabele toe te voegen, verschijnt er een zijpaneel waarin u de volgende details moet verstrekken.
Naam | De naam van uw berekende variabele en hoe deze in verschillende weergaven wordt gepresenteerd. |
Beschrijving | De beschrijving van uw berekende variabele die in het systeem zichtbaar zal zijn als referentie naar de berekende variabele. |
Externe ID | Een ID voor het refereren naar deze specifieke variabele bij gebruik van de API. |
Formule | Hier definieert u de berekening van uw variabele. |
Primaire invoer | De primaire invoer is de eerste variabele die u wilt gebruiken voor uw berekening. U kunt kiezen uit de standaardvariabelen en ook uit forecast variabelen en configuraties als u Neo Forecast geactiveerd heeft voor uw organisatie. Dit zal de invoergegevens zijn vóór de operator. |
Aangepaste invoer | Hiermee kunt u een specifiek getal toevoegen aan de aangepaste variabelevergelijking in plaats van een tweede variabele. Let op dat er geen berekening zal worden uitgevoerd als de gegevens van de primaire invoer 0 zijn. Deze berekeningen worden uitgevoerd op de resolutie waarop uw invoergegevens zijn ingesteld; 5min, 15min, 30min, 60min. |
Operator | De operator bepaalt wat er moet gebeuren met de gegevens die u kiest om een berekende variabele mee te maken. De beschikbare operators zijn:
|
Secundaire invoer | De Secundaire invoer is de tweede variabele die u wilt gebruiken voor uw berekening. U kunt kiezen uit de standaardvariabelen en ook uit Forecast variabelen en configuraties als u Neo Forecast geactiveerd heeft voor uw organisatie. Dit zal de invoergegevens zijn na de operator. |
Zichtbaarheid | Bepaalt in welke weergavegroepen de invoergegevens worden weergegeven. |
Weergeven in dashboard | Bepaal of dit zichtbaar moet zijn in de dashboardweergave. Momenteel worden variabelen met salaris kostencalculaties niet getoond in het dashboard. |
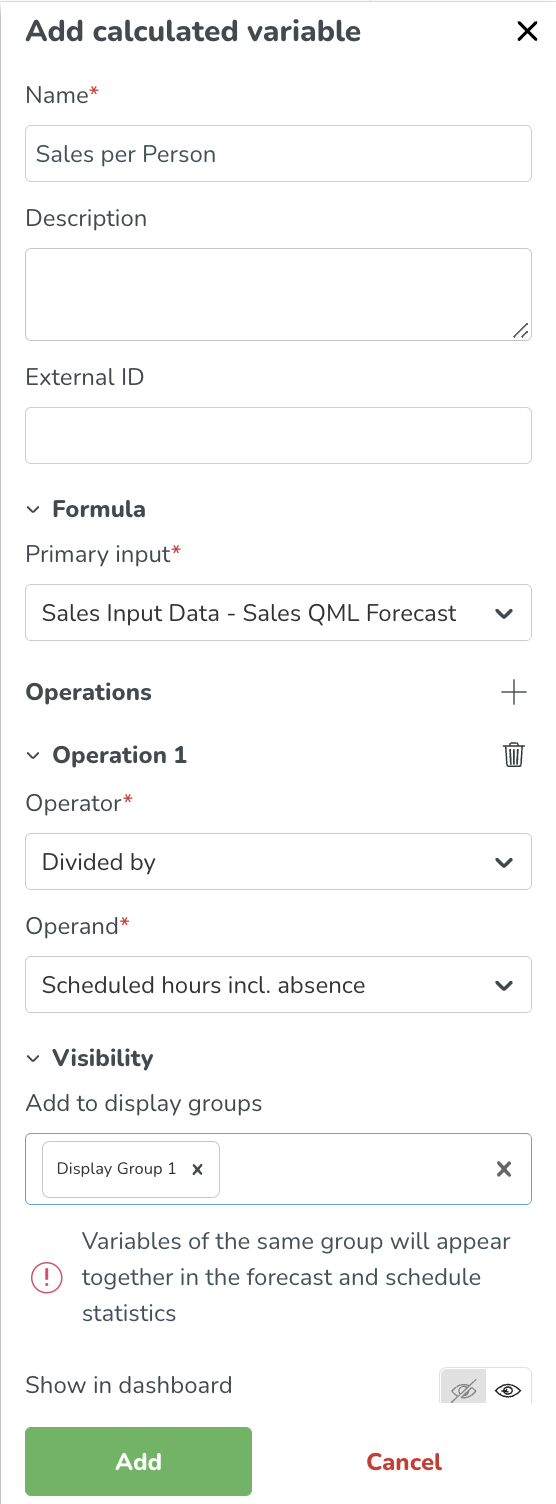
Voorbeeld van een berekende variabele
Voorspelde verkoop per geplande personeelsuur is een veelgebruikte KPI binnen veel sectoren.
Om zo'n variabele te creëren, moet u een prognose geconfigureerd hebben om een voorspelde verkoopwaarde te hebben. Quinyx kan deze voorspelling automatisch genereren met AI - waarbij uw organisatie de daadwerkelijke verkoop levert.
Lees meer over Algoritmen en voorspellingen "hier".
- Primaire Invoer: Verwachte verkoop
- Operator: Gedeeld door
- Secundaire invoer: Geplande uren
Voorbeeld van een berekende variabele met meerdere operators
We zullen dit wilde voorbeeld gebruiken om te laten zien hoe meerdere bewerkingen worden berekend.
De berekening wordt uitgevoerd waarbij de totalen van elke bewerking in de volgende bewerking worden gebruikt. Aan de hand van het onderstaande screenshotvoorbeeld wordt de berekening als volgt uitgevoerd:
- Optimale uren + Geplande uren = x
- x + Gewerkte uren = y
- y + Aangepaste invoer = z
- z / aangepaste invoer = uitvoer weergegeven in de GUI
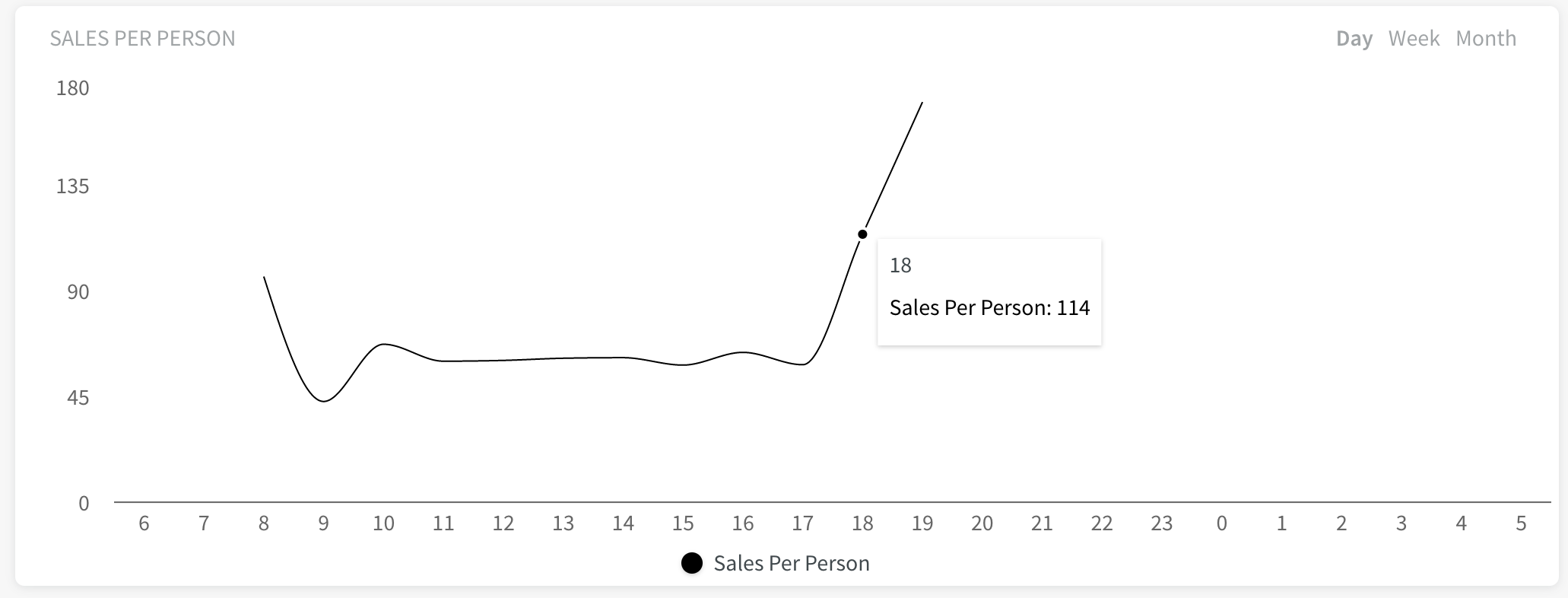
Bekijk berekende variabelen in het Dashboard
Een berekende variabele heeft een aparte grafiek in het Quinyx dashboard. Het zal nog steeds de opties hebben voor het selecteren van de huidige dag, huidige week en huidige maand - op dezelfde manier als de bestaande widgets vandaag in het dashboard zijn.
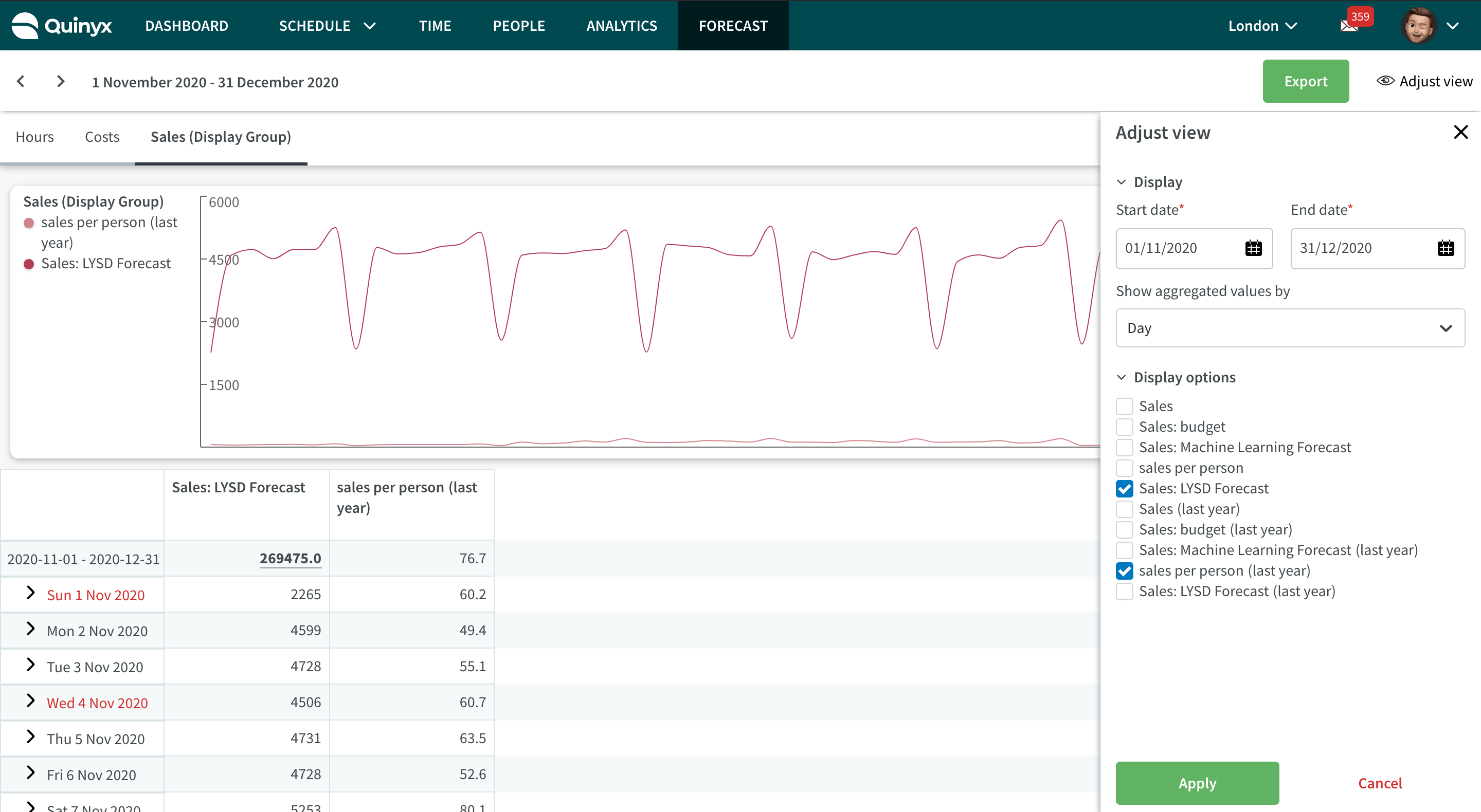
Bekijk berekende variabelen in het Prognose Overzicht
De berekende variabele moet worden toegevoegd aan een weergavegroep om op de Prognoseoverzicht pagina te worden weergegeven.
Selecteren van Aggregatietype op variabelen
Het aggregatietype bepaalt hoe gegevens worden weergegeven in de dagelijkse, wekelijkse en maandelijkse weergaven.
U hebt de optie om het aggregatietype te selecteren op Input Data, Forecast Configuration, Calculated variable, of Optimal Headcount variabelen op de pagina Variabele instellingen . Bij het selecteren van het aggregatietype, kiest u tussen Gemiddelde en Som voor elke variabele.
- Som: Wanneer Som is geselecteerd, worden er geen wijzigingen aangebracht in de huidige berekeningen van geaggregeerde data.
- Gemiddelde: Wanneer Gemiddelde is geselecteerd, wordt in plaats van de waarden op te tellen om de dagelijkse totaal te tonen, door Quinyx het dagelijkse gemiddelde getoond. Dit geldt ook bij het bekijken van data in de dagelijkse, wekelijkse of maandelijkse weergave. Het gemiddelde wordt berekend door rekening te houden met de waarden van elke bucket met bestaande data en vervolgens de gemiddelde waarde te berekenen op basis van dat aantal buckets.
Voor Forecast Configuration-variabelen is het aggregatietype standaard hetzelfde aggregatietype als dat van de onderliggende Input Data.
Standaard hebben alle bestaande Input Data, Forecast Configuration, of Optimal Headcount-variabelen Som als hun aggregatietype, en zodoende worden er geen aanpassingen gemaakt aan de huidige aggregatieberekeningen. Wanneer u een nieuwe variabele toevoegt, zullen Input Data-variabelen standaard Som hebben terwijl Optimal Headcount variabelen standaard Gemiddelde als het geselecteerde aggregatietype zullen hebben.
Hoe werkt het?
Quinyx zorgt ervoor dat de berekening in alle gevallen op elk granulariteitsniveau wordt uitgevoerd. De onderstaande voorbeelden zijn specifiek voor berekende variabelen, inclusief meerdere variabelen van hetzelfde of van verschillende aggregatietypen. Voor normale invoergegevens, prognoseconfiguratie of optimale personeelbezetting voert Quinyx het algemene gemiddelde of de som uit. Het is anders voor berekende variabelen, omdat je bij berekende variabelen eigenlijk niet de optie hebt om een aggregatietype te kiezen, maar de aggregaties worden berekend op basis van de onderstaande voorbeelden.
Voorbeeld 1
- Variabele A (aggregatietype som)
- Variabele B (aggregatietype gemiddelde)
- Berekende variabele C: A/B
- Dagelijkse C = dagelijkse (som) A / dagelijkse (gemiddelde) B
De berekening van Dagelijkse C wordt uitgevoerd op basis van de dagelijkse waarden van de onderliggende variabelen.
Voorbeeld 2
- Variabele A (aggregatietype som)Variabele B (aggregatietype som)
- Variabele C (aggregatietype som)Berekende variabele D: A+B-C
- Dagelijks D = dagelijks (som) A + dagelijks (som) B - dagelijks (som) C
De berekening van Dagelijks D wordt uitgevoerd op basis van de dagelijkse waarden van de onderliggende variabelen.
Voorbeeld 3
- Variabele A (aggregatietype som)Berekende variabele B: A+100 (aangepaste invoer)
- Dagelijks B = dagelijks (som) A + 100
De berekening van Dagelijks B voegt de aangepaste invoer toe zoals gedefinieerd in de berekende variabelen, niet als een som van de toevoeging van de aangepaste invoer op de laagste granulariteit.
Optimale Personeelbezetting Variabelen
Klanten die statische en dynamische regels gebruiken in combinatie met hun geprognosticeerde invoergegevens om een optimale personeelbezetting te genereren, moeten een Optimale Personeelbezetting Variabele creëren die aan die regels is gekoppeld.
Navigeer naar Toevoegen > Optimale Personeelbezetting.
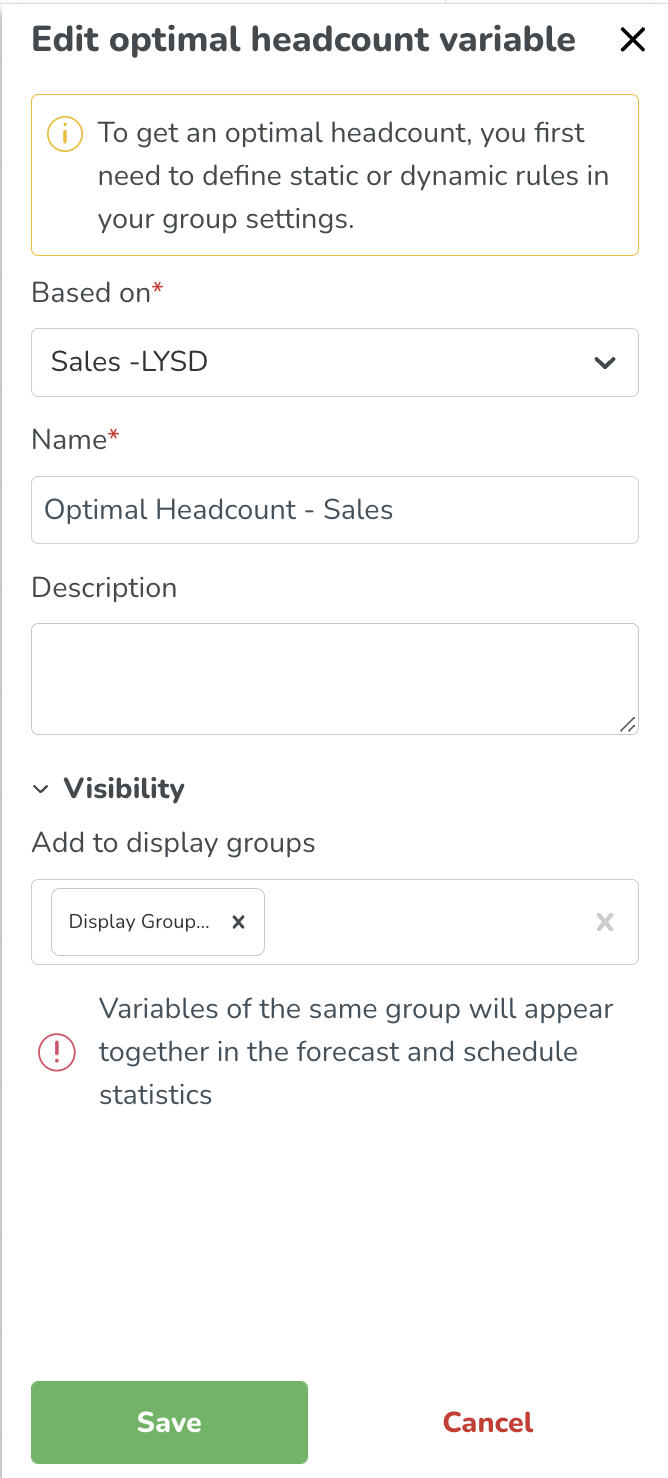
Gebaseerd Op | Op welke set regels moet de berekening van de optimale personeelbezetting gebaseerd zijn - hier ziet u automatisch alle prognoseconfiguraties die zijn gemaakt en die statische of dynamische regels eraan gekoppeld hebben. In de toekomst zullen we ondersteuning toevoegen voor alleen statische regels. Zodra de variabele is aangemaakt, wordt de berekening automatisch uitgevoerd. |
Naam | Hoe u uw Optimal Headcount Variable wilt noemen. |
Beschrijving | Een beschrijving van deze variabele om deze gemakkelijk te kunnen identificeren. |
Aggregatietype | Het aggregatietype bepaalt hoe gegevens worden weergegeven in de dagelijkse, wekelijkse en maandelijkse weergave. Kies Som of Gemiddelde. |
Zichtbaarheid | Bepaalt in welke weergavegroepen de invoergegevens worden weergegeven. U kunt beheren hoe de variabele verschijnt op de forecast- en planningpagina's in Beheer weergavegroepen. |
De Optimal headcount variable wordt nu weergegeven in uw variabelenlijst binnen de weergavegroep waaraan u deze hebt toegewezen, of als niet gegroepeerd als u deze nog niet hebt toegewezen.

Weergavegroepen
Weergavegroepen zijn een manier om invoergegevens, standaardvariabelen, optimale personeelbezetting variabelen en berekende variabelen in een enkele groep te groeperen, zodat ze samen worden weergegeven op grafieken en tabellen binnen de Prognoseoverzicht en binnen Planningsstatistieken.
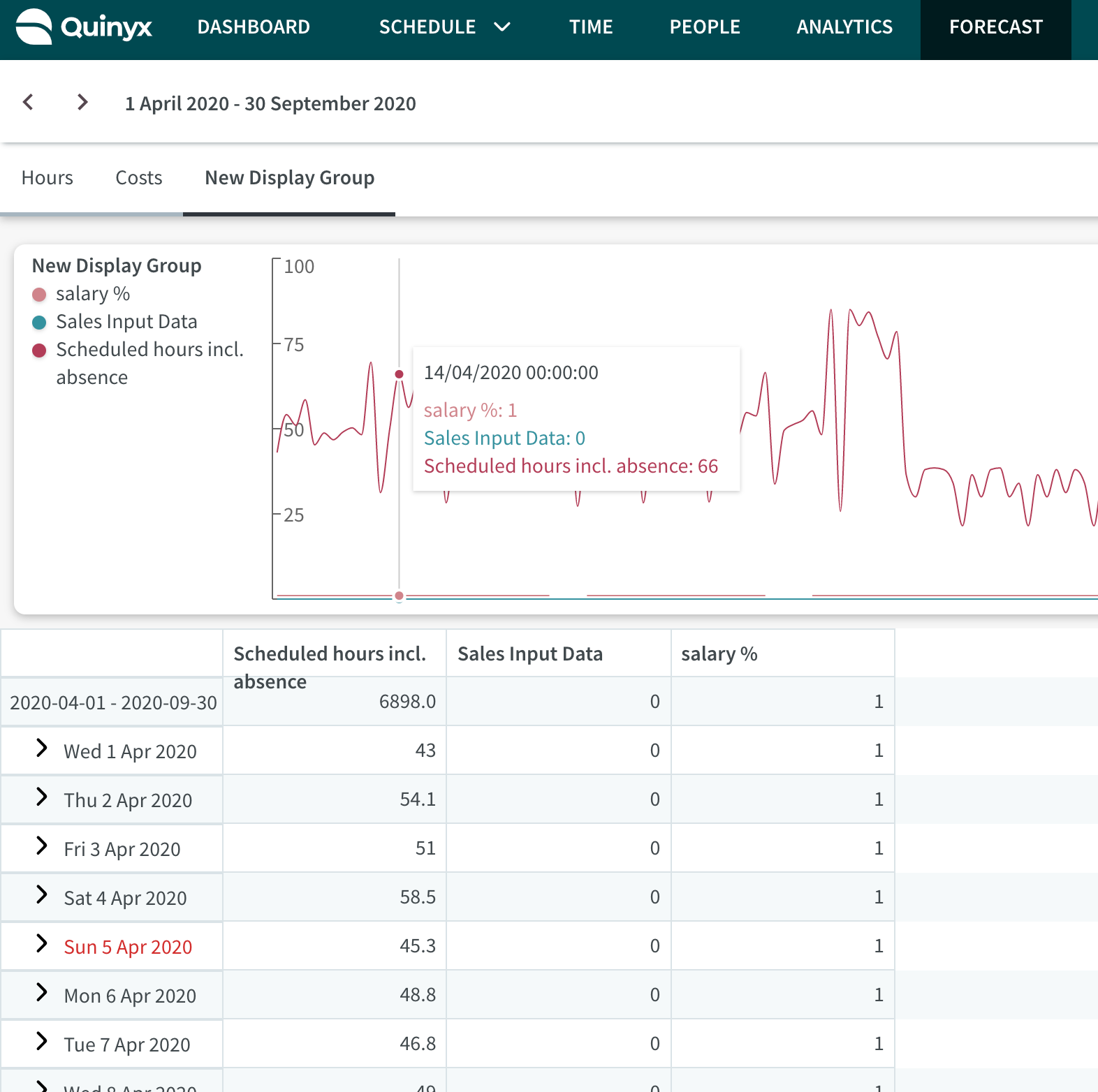
Standaard heeft Quinyx twee weergavegroepen: Kosten en Uren. We hebben ook een derde standaard weergavegroep genaamd Arbeid, die automatisch wordt toegevoegd als u een optimale personeelbezetting creëert met de Optimale Personeelsbezetting & Arbeidsnormen - NIEUW functionaliteit. U kunt de variabelen binnen deze groepen nog steeds beheren. Lees verder om te leren hoe dit wordt gedaan.
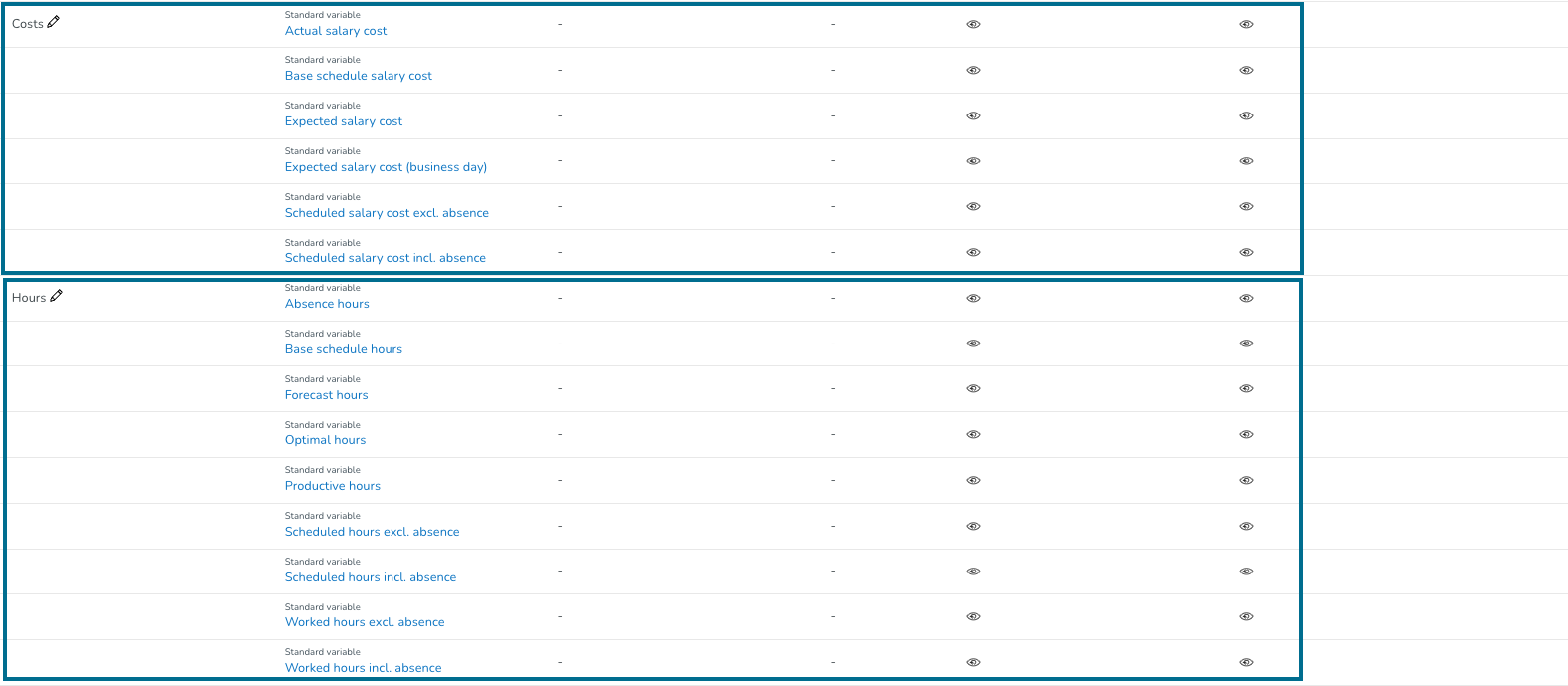
Om een nieuwe weergavegroep te maken, klikt u op Beheer Weergavegroepen bovenaan de pagina.
Dit opent een venster met alle huidige weergavegroepen. Klik op de + om een nieuwe groep te maken.
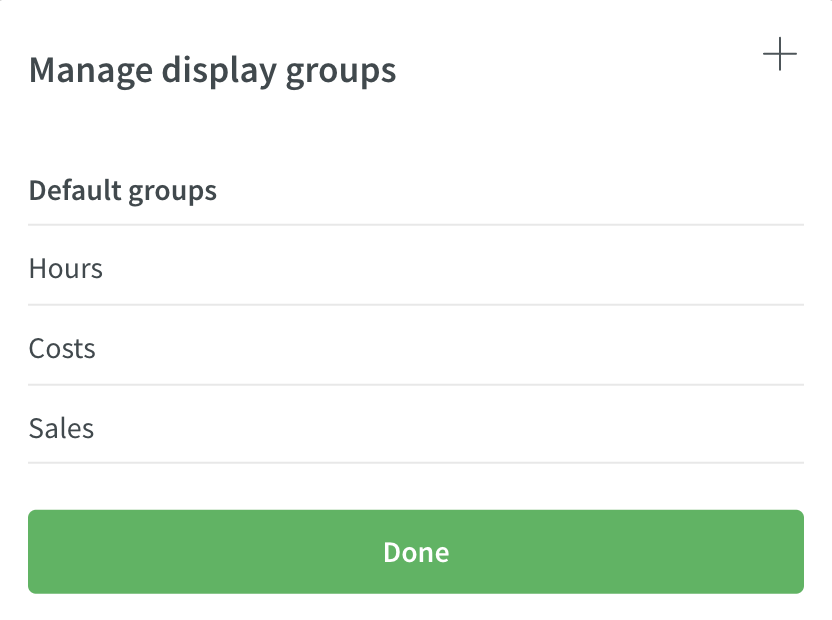
Voer de naam van uw nieuwe weergavegroep in, selecteer welke variabelen u samen in deze groep wilt weergeven en klik op Volgende.
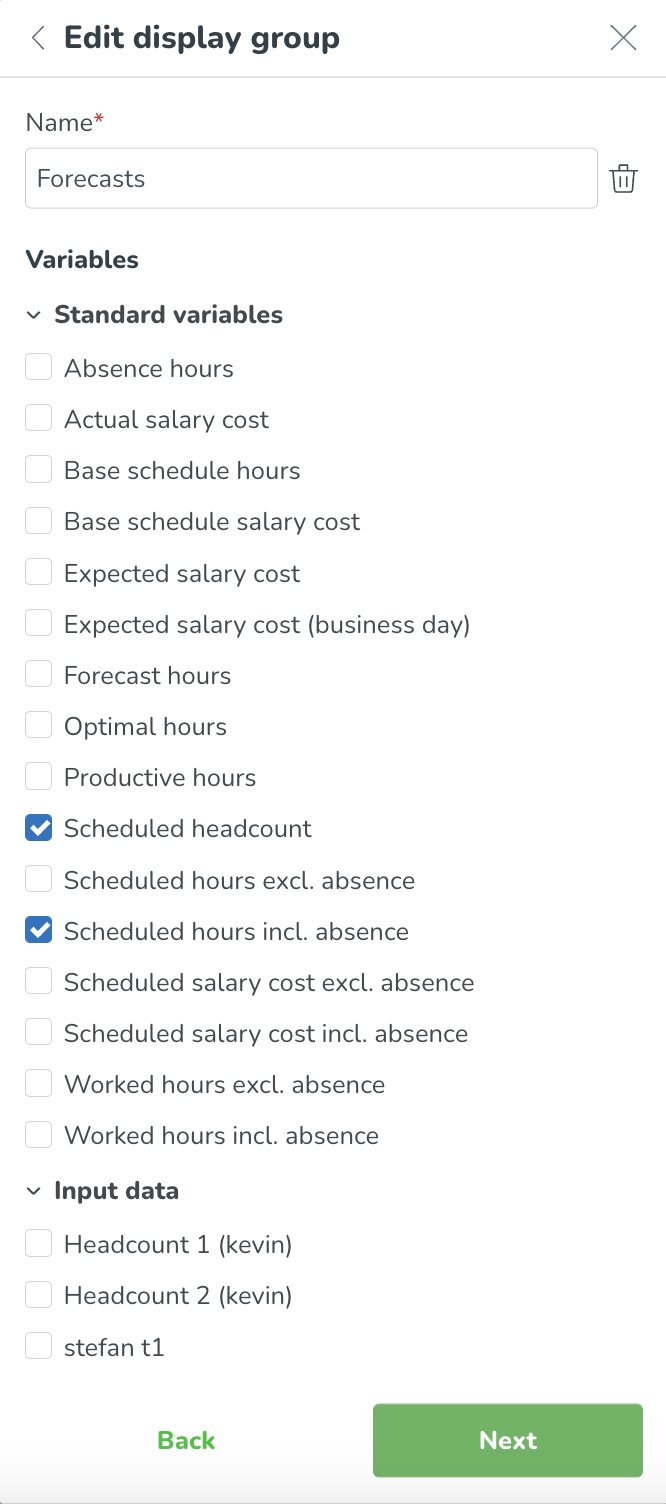
Op de volgende pagina kunt u kiezen welke variabelen u zichtbaar wilt maken in planningsstatistieken en het prognose tabblad. Klik op Toepassen om uw wijzigingen op te slaan.
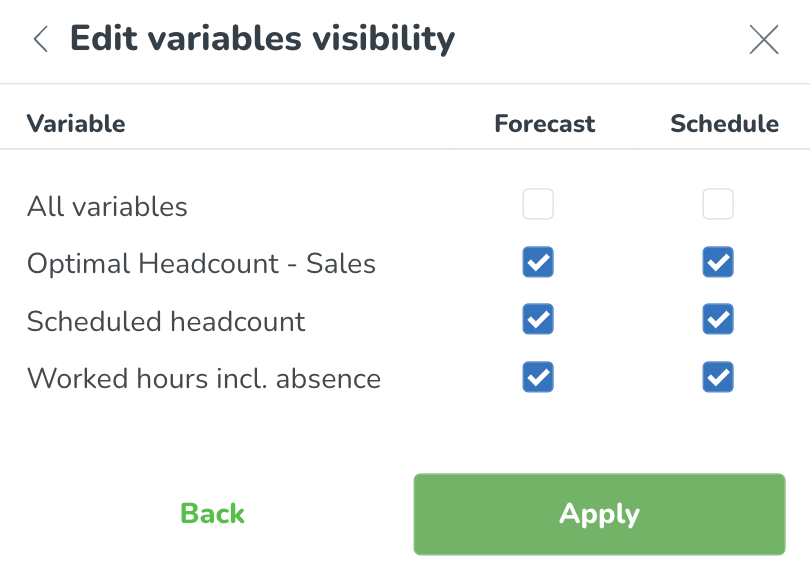
Uw nieuwe groep is aangemaakt en wordt nu weergegeven in de lijst met beheersbare weergavegroepen.

U kunt de naam bewerken door te klikken op Beheer weergavegroepen > vervolgens het potlood, of u kunt de weergavegroep verwijderen door op de prullenbak te klikken.
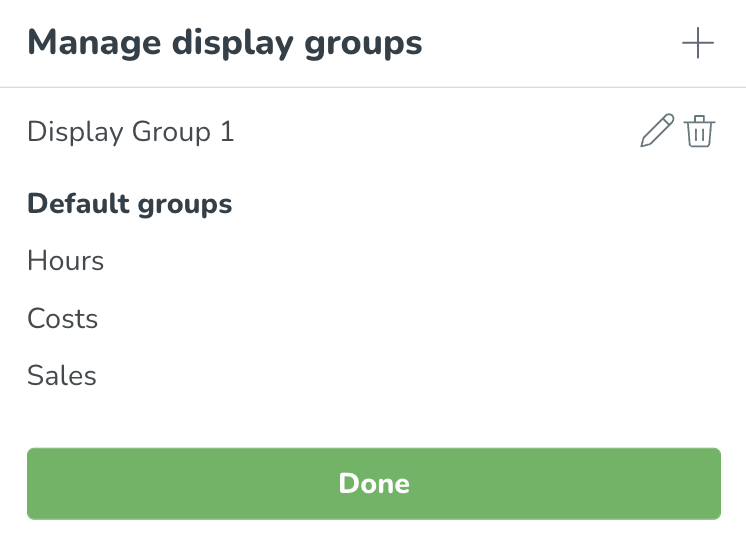
Door op het potloodicoon te klikken, kunt u de variabelen bewerken die u binnen de weergavegroep wilt tonen. Vergeet niet dat de variabelen die u hier selecteert samen worden weergegeven in grafieken en tabellen.
U kunt nu naar de Planning of Prognose tabbladen navigeren om de variabelen binnen de weergavegroepen te bekijken en te beheren.
Groepen weergeven in Planning Statistieken

Groepen weergeven in Prognose