Du behöver ha köpt Prognosmodulen för att konfigurera och använda denna lösning.
Optimal bemanning beräknad genom den nya funktionaliteten för optimal bemanning och arbetsstandard kan användas av Auto-schema-algoritmen för att skapa scheman. Kontakta Quinyx för att få hjälp med att ställa in det.
Observera att denna nya funktion för att beräkna optimal bemanning och arbetsstandarder kommer så småningom att ersätta de befintliga statiska och dynamiska regellösningarna samt arbetsstandardberäkningar genom Pythia (AI-Optimering), när alla funktioner har integrerats. Dock kan dessa metoder för närvarande fortfarande användas samtidigt. Vi kommer att dela ytterligare information om detaljerna kring denna migration vid ett senare tillfälle.
Introduktion
Vill du ställa in variabler för optimal bemanning och arbetsstandarder i Quinyx? Nedan finns anvisningar om hur du kan göra detta.
Vad är arbetsstandarder?
Beräkningen av arbetsstandard är beräkningen som översätter den prognostiserade efterfrågan av en efterfrågedrivare (antal besökare, försäljning, etc.) till en krävd bemanningskurva per roll baserat på produktivitetsstandarder.
Exempel - Antalet kassörer som behövs beror på antalet transaktioner som behandlas. - För att ställa in antalet kassörer per transaktion som behandlas, behöver kunden veta i genomsnitt hur lång tid det tar för en anställd att behandla en transaktion eller hur många kassörer som skulle behövas för att hantera ett visst antal transaktioner.
Generellt sett kan arbetsstandarder konfigureras för specifika bemanningsvariabler, för specifika grupper (regioner, enheter eller avdelningar) och för specifika tidsperioder. Tidsperioden är också viktig eftersom det kan vara så att teamens produktivitet ökar (till exempel om du köper en ny kaffemaskin kan du förvänta dig att dina baristor blir snabbare på att förbereda kaffe), och det bör också återspeglas i uppdaterade arbetsstandarder. Sådana förändringar i produktivitet beaktas i bemanningsberäkningen när förändringarna har tillämpats.
Resultatet av arbetsstandardberäkningen är en optimal bemanningskurva som kan användas som grund för manuell schemaläggning, basplanering och automatisk schemaläggning för att skapa ett schema som matchar efterfrågan.
Förutsättningar
För att kunna använda arbetsstandarder för att beräkna din optimala bemanning krävs följande steg:
Skapa en prognos (manuell, extern eller Quinyx Demand Forecasting) på en 15, 30 eller 60-minuters nivå.
Skapa variabeln för optimal bemanning
Du kan skapa din optimala bemanning under Variabelinställningar.
När du loggar in på ditt konto, klicka på pilen nedåt bredvid det övre högra hörnet på sidan och välj sedan Optimeringsinställningar. När du är i Variabelinställningar, klicka på Lägg till.
För närvarande öppnas variabelinställningarna omedelbart när du går in i Optimeringsinställningar.
Klicka på Lägg till > Optimal bemanning och arbetsstandarder NY. Den optimala bemanningen tillåter fortfarande användare att fortsätta använda och lägga till optimal bemanning som ska beräknas genom statiska och dynamiska regler.
Du kommer då att behöva fylla i relevant allmän information om den optimala bemanningsvariabeln.
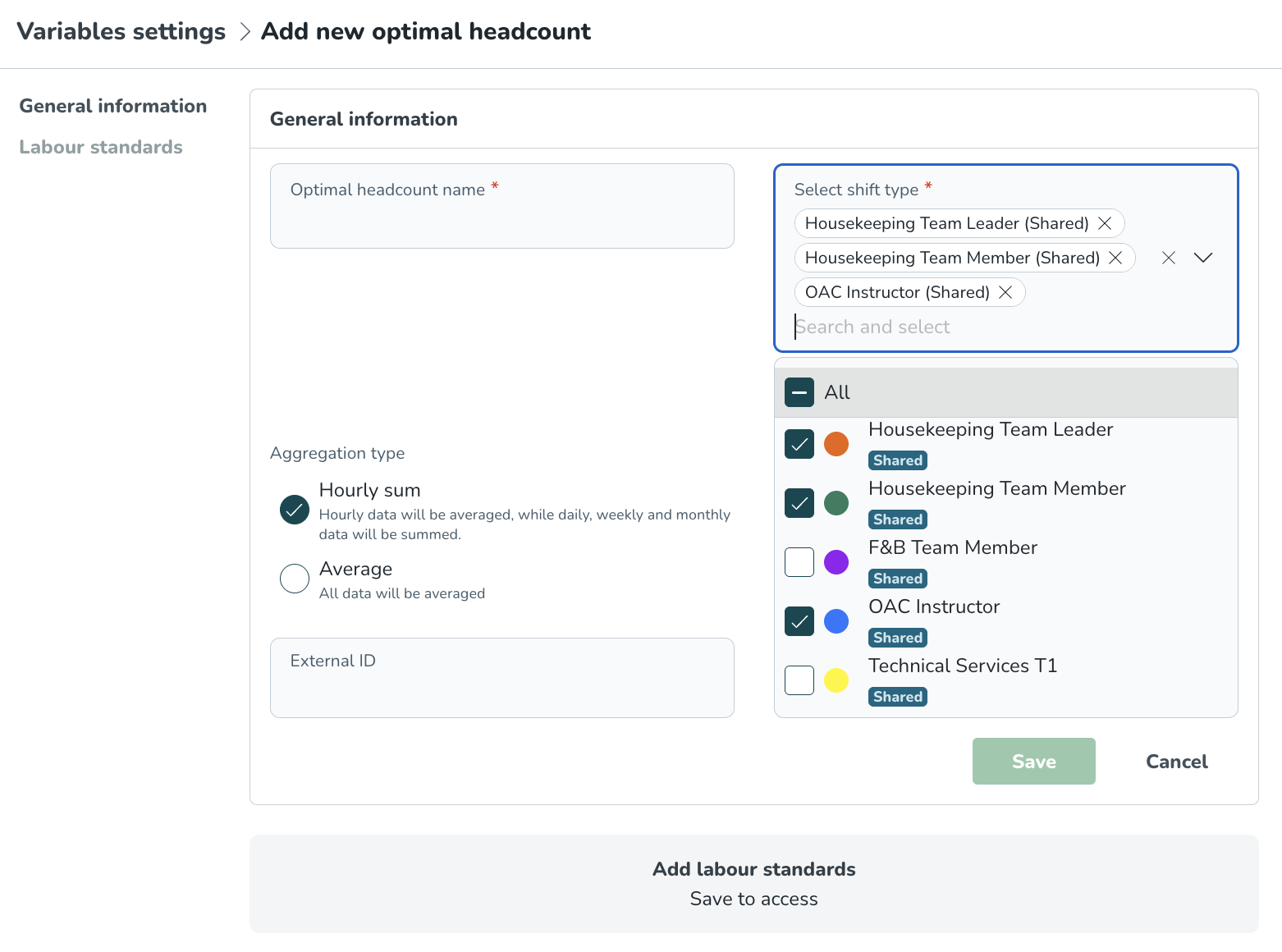
Optimalt bemanningsnamn och Välj skifttyp är obligatoriska fält.
Optimalt bemanningsnamn*: Detta fält är för dig att ange namnet du vill att din optimala bemanningsvariabel ska kallas. Till exempel kan detta vara rollen som kassör eller chef som du lägger till bemanningsberäkningen för.
Välj skifttyp(er)*: Detta fält är för dig att välja de specifika skifttyperna för denna optimala bemanning. Till exempel kan du välja Kvällsskift 17:00 - 23:00, Kassör, Städare, eller Morgonskift 9:00 - 12:00, beroende på dina skifttyper, etc. Du måste välja en skifttyp eftersom i visualiseringen i schemastatistik- och prognosfliken kan du tydligt jämföra optimal bemanning jämfört med schemalagd bemanning för den specifika rollen/bemanningen.
När du skapar optimal bemanning baserat på lokala skifttyper kommer endast enheter och avdelningar som de lokala skifttyperna är relaterade till att returneras till gruppträdet vid konfigurering av arbetsstandarder. Namnet på enheten/avdelningen visas bredvid namnet på den lokala skifttypen. Detta säkerställer att inga enheter kan väljas där de lokala skifttyperna inte existerar, och det blir tydligare vilka specifika enheter de lokala skifttyperna tillhör.
Aggregeringstyp: Aggregeringstypen avgör hur data visas i de dagliga, veckovisa och månatliga vyerna.
Genomsnittligt: Den genomsnittliga aggressionsmetoden används om du vill veta hur många anställda du behöver schemalägga i genomsnitt under dagen.
Summa per timme: Aggressionsmetoden summa per timme används om du vill veta hur många timmar du behöver schemalägga under en dag, som du sedan ska fördela på medarbetare och skift.
Du kan klicka här för att läsa mer om aggressionsmetoden summa per timme.
Lägg till i Visningsgrupper: Välj den relevanta visningsgruppen. Variabler i samma visningsgrupp kommer att visas tillsammans i prognos och schemastatistiken. Bemanningvariabeln läggs automatiskt till i Arbete-visningsgruppen.
När de allmänna detaljerna för din optimala bemanningsvariabel har fyllts i, klicka på Spara.
Du kan inte lägga till dina arbetsregler inom arbetsstandarder-avsnittet.
Skapa arbetsstandarder
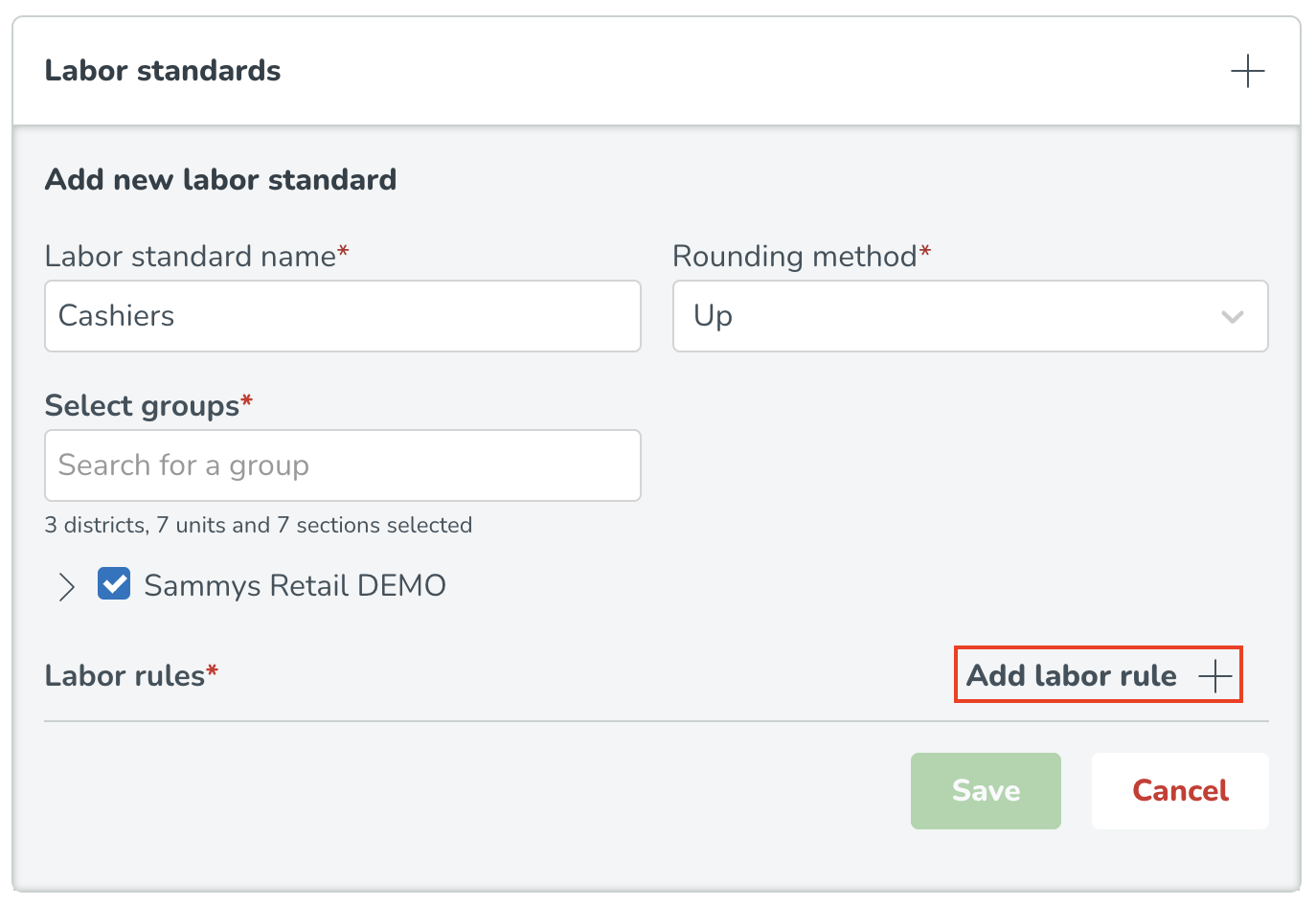
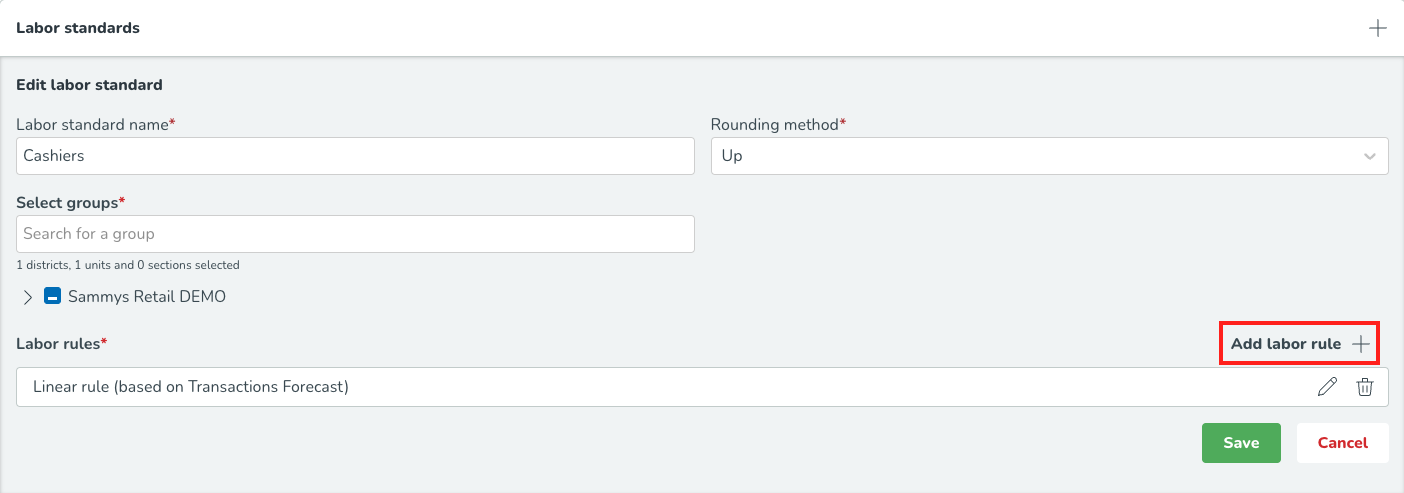
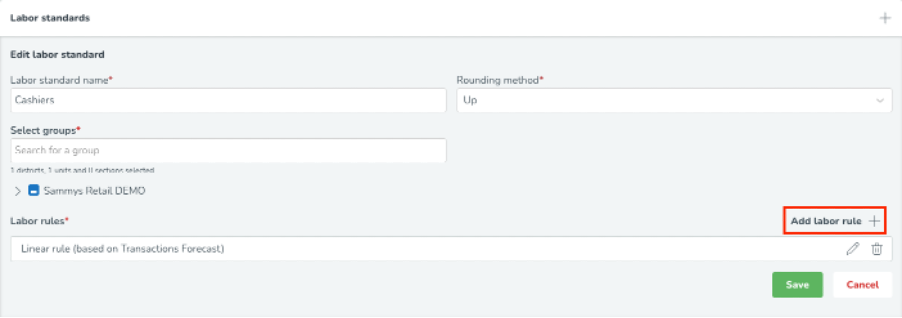
Efter att ha konfigurerat den allmänna informationen om den optimala bemanningsvariabeln är det dags att definiera de specifika arbetsstandarderna som ska användas för att bestämma optimal bemanning. Olika arbetsstandarder kan ställas in för olika grupper för att fånga skillnader i genomsnittliga produktivitetsstandarder över distrikt, enheter och avdelningar. För att konfigurera detta kommer du att se följande sida där du väljer + knappen bredvid Arbetsstandarder.
Du kommer sedan att se följande sida.
Fyll sedan i följande:
Arbetsstandardens namn* Detta är namnet du vill kalla arbetsstandarden. Det är relevant när du har olika arbetsstandarder för olika grupper (regioner, enheter) och vill se till att du kan skilja mellan dessa olika produktivitetsstandarder.
Avrundningsmetod* Du har fyra alternativ: Upp, Närmast, Ned och Ingen avrundning. Detta anger om, när resultatet av personalbehovsberäkningen resulterar i ett decimaltal, personalbehovet ska avrundas uppåt, nedåt eller till närmaste heltalsvärde. Decimaltal som slutar på .5 kommer alltid att avrundas uppåt när Närmast är valt.
Avrundningsregeln som ställts in i arbetskonfigurationen påverkar endast avrundningen på den lägsta granulära nivån. Till exempel, om det behövda antalet anställda är 4,33 från 10:00-10:15 och avrundningsmetoden är uppåt då kommer den optimala bemanningen för dessa 15 minuter att vara 5.
Det finns ingen avrundning tillämplig på timnivåer (om inte det är den lägsta granulära nivån). Om den optimala bemanningen är 1 för den första delen av timmen och 2 för den andra delen, kommer den optimala bemanningen att visa 1,5. Om timnivån är den lägsta granulära nivån och den behövda bemanningen är 4,33 med avrundningsmetoden uppåt vald, då ska den optimala bemanningen för den timmen vara 5.
Det finns ingen avrundning på daglig/veckovis/månadsnivå. Dessa värden följer de regler som är konfigurerade för den optimala bemanningsvariabeln (värdena summeras eller medelvärdesberäknas, inte avrundas uppåt).
Avrundningslogiken för timvärden som tillämpas på de schemalagda värdena för antal anställda kommer också att tillämpas på de optimala värdena för antal anställda.
Lägg till valda grupper* Detta alternativ gör att du kan välja från din hierarki till vilka grupper du vill att denna arbetsstandard ska gälla. Anledningen till att detta alternativ är obligatoriskt är att du har möjligheten att välja några eller alla enheter i din hierarki. Du kan välja hela organisationen eller specifika regioner, enheter eller avdelningar för varje arbetsstandardkonfiguration eftersom du kanske vill skapa mer än en arbetsstandard för olika enheter. När en grupp har lagts till i en specifik arbetsstandardkonfiguration kan du inte välja den gruppen inom en annan arbetsstandardkonfiguration; den kommer istället att vara gråmarkerad.
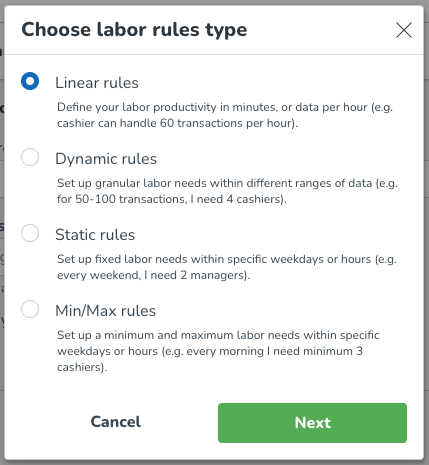
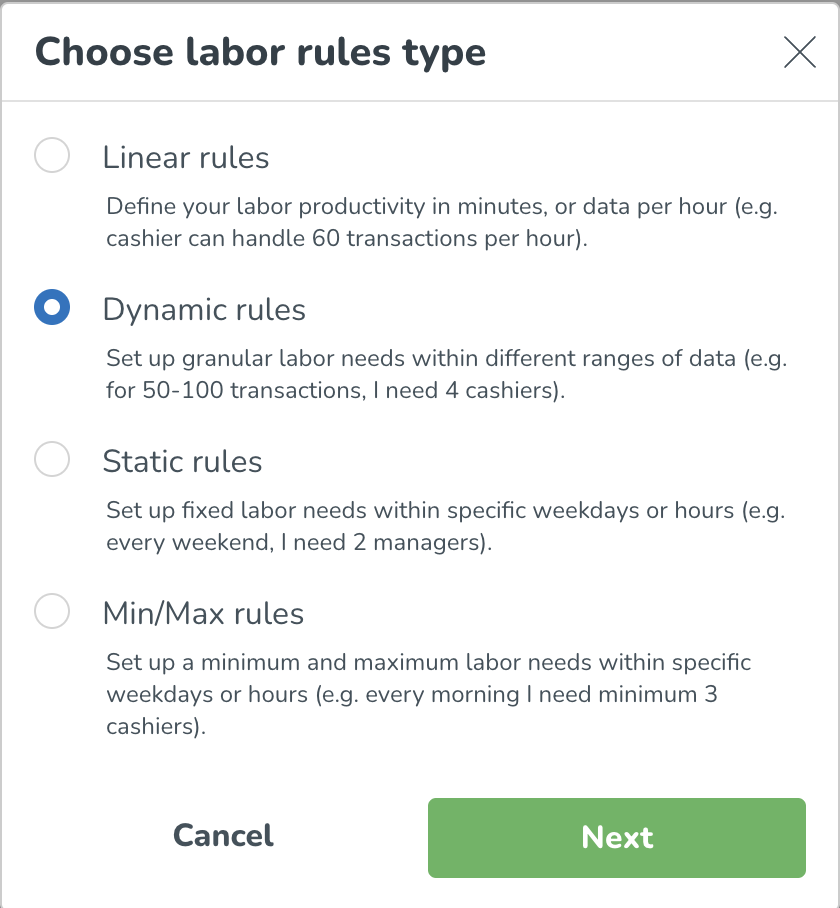
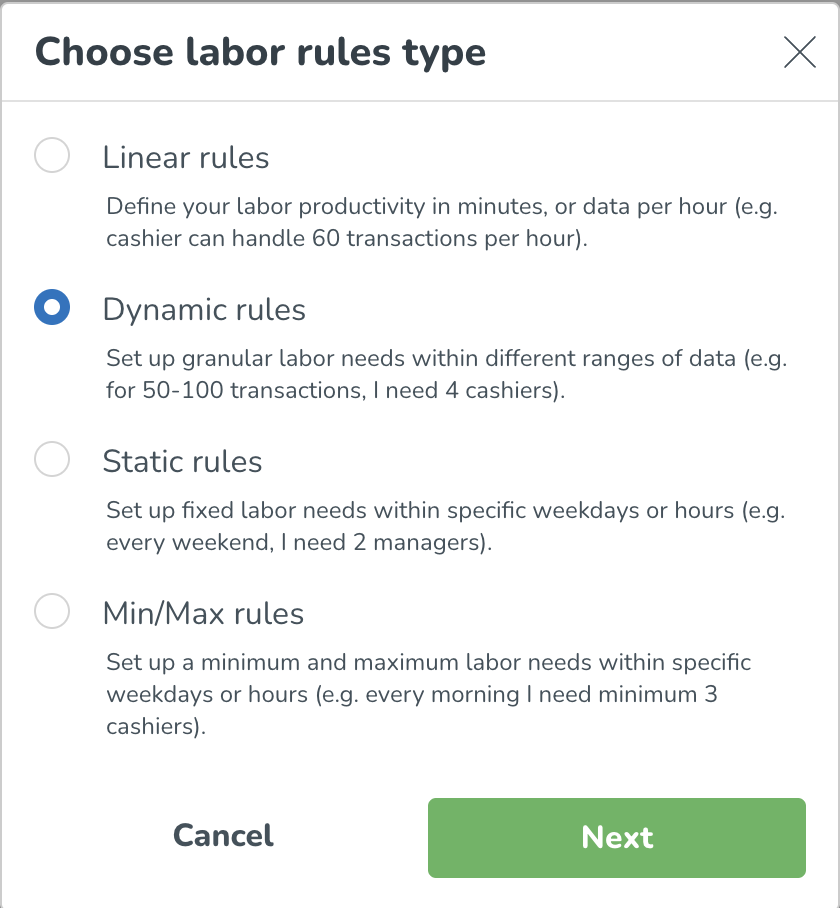
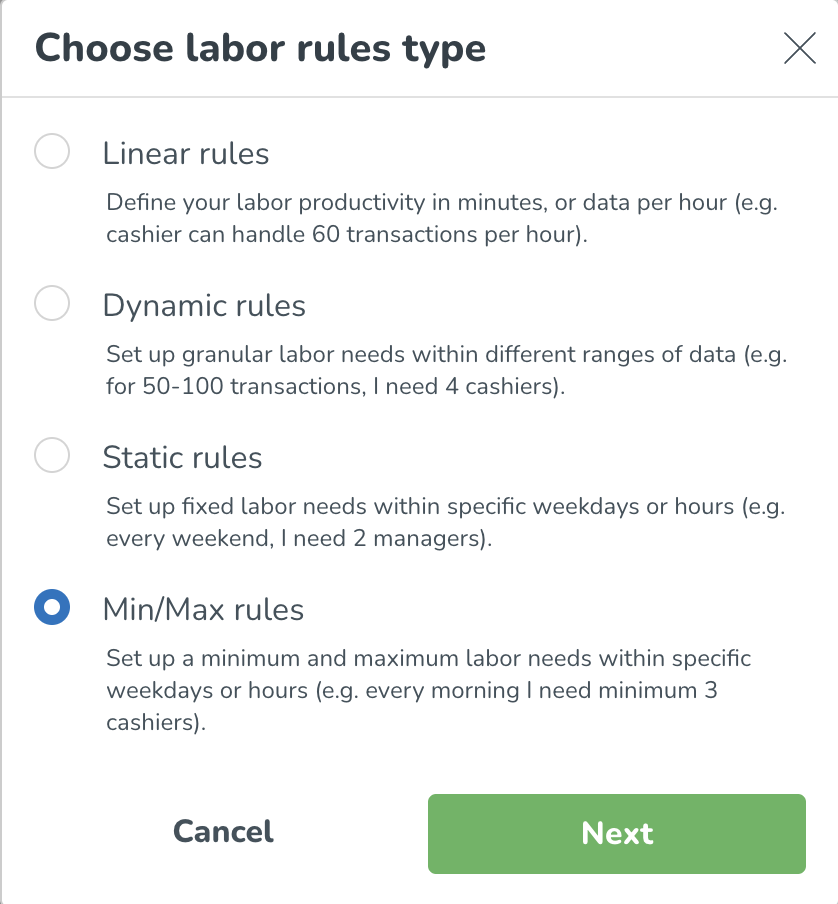
Därefter lägger du till en arbetsregel. Arbetsregeln inkluderar de specifika produktivitetsberäkningsdetaljer du vill tillämpa på din valda grupp. Klicka på Lägg till arbetsregel + knappen, du kommer sedan att se följande. Välj arbetsregeltyp(er) som är tillämpliga för dig inom din organisation.
Skapa arbetsstandarder med linjära regler
Vad är linjära regler?
När du ställer in linjära arbetsregler i dina arbetsstandarder för din specifika optimala bemanningsvariabel har du två formatalternativ att välja mellan:
Data Per Timme: Till exempel, om det tar en kassör 2 minuter per transaktion och vi förutspår 60 transaktioner mellan kl. 10-11, skulle vi behöva 2 kassörer mellan kl. 10-11.
Minuter Per Data: Till exempel, om det tar en kock 5 minuter att förbereda en burgare, och vi förutspår 24 burgarbeställningar mellan kl. 10 och 11, skulle vi behöva 2 kockar mellan kl. 10 och 11. Men eftersom vi också förutspår att kunderna kommer att beställa 30 pommes frites, och det tar en kock 2 minuter att förbereda pommes frites, behöver vi totalt sett 3 kockar mellan kl. 10 och 11.
Hur konfigurerar du linjära regler?
Ingen enskild format används konsekvent för att definiera produktivitetsnivåer över branscher när man använder den linjära metoden. Vissa branscher föredrar att använda Minuter per data medan andra föredrar att använda Data per timme.
Här har du flexibiliteten att välja det format du är bekant med för att säkerställa att konfigurationen är så enkel som möjligt att underhålla.
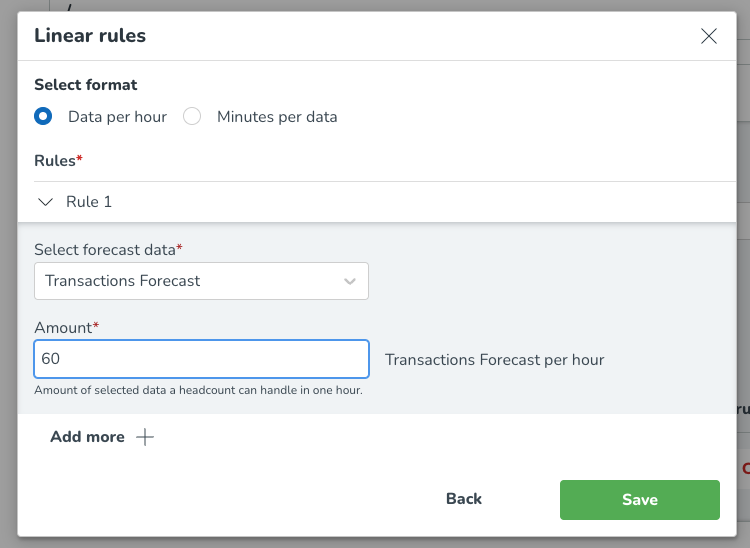
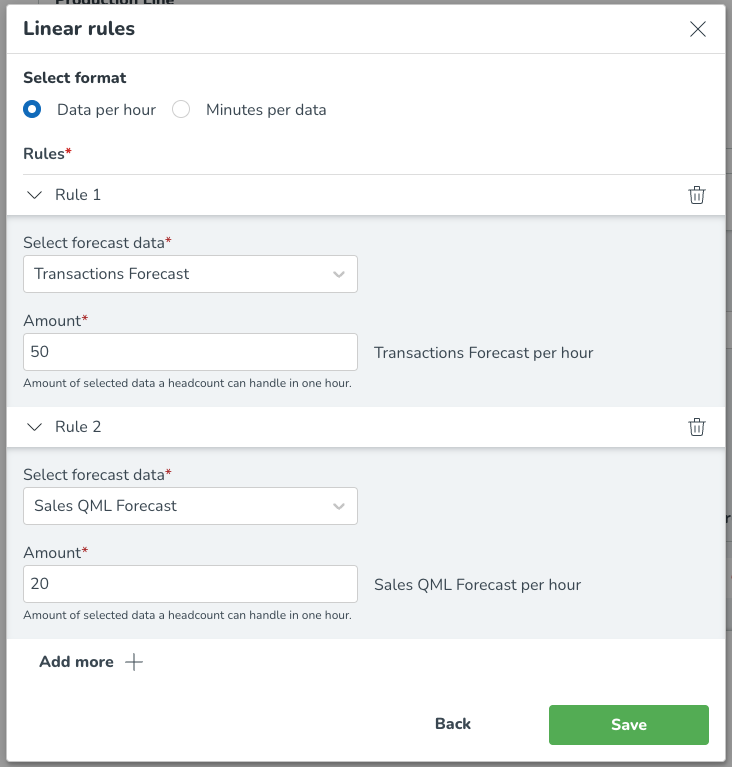
För Data per timme, som ses i bilden nedan, välj formatet (data per timme), vilket gör att du kan välja prognosdata som personalbehovet baseras på och ange det nödvändiga beloppet. Du kan välja Lägg till mer för att lägga till ytterligare arbetsregler baserade på andra prognosdatavariabler.
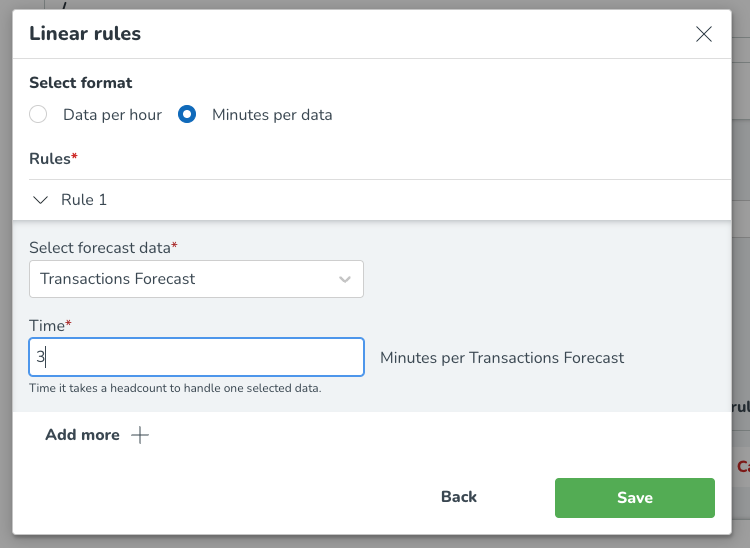
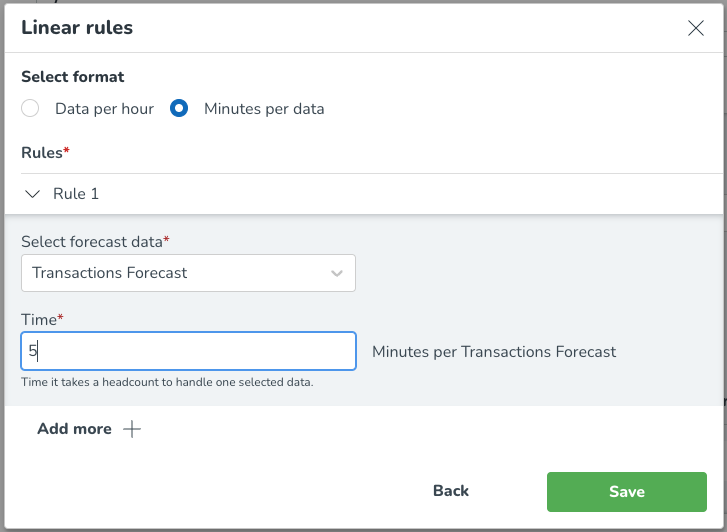
För Minuter per data, som ses i bilden nedan, välj formatet (minuter per data), vilket gör att du kan välja prognosdata som personalbehovet baseras på och ange de nödvändiga minuterna per vald prognosvariabel. Du kan välja Lägg till mer för att lägga till ytterligare arbetsregler baserade på andra prognosdatavariabler.
När det nödvändiga formatet har valts och den obligatoriska informationen har angetts, klicka på Spara.
Du kan se de ifyllda versionerna av båda formaten för arbetsregeln nedan.
Data per timme
I det här exemplet har vi valt att antalet kassörer beror på antalet transaktioner, där en kassör kan hantera 12 transaktioner på en timme. Det innebär att när prognosen för transaktioner förutspår 24 transaktioner inom en specifik timme, skulle vi behöva 2 kassörer för att täcka den efterfrågan.
Minuter per data
I det här exemplet har vi valt att antalet kassörer beror på antalet transaktioner, där en kassör kräver 5 minuter för att hantera en transaktion. Det innebär att när prognosen för transaktioner förutspår 24 transaktioner inom en specifik timme, skulle vi behöva 2 kassörer för att täcka den efterfrågan.
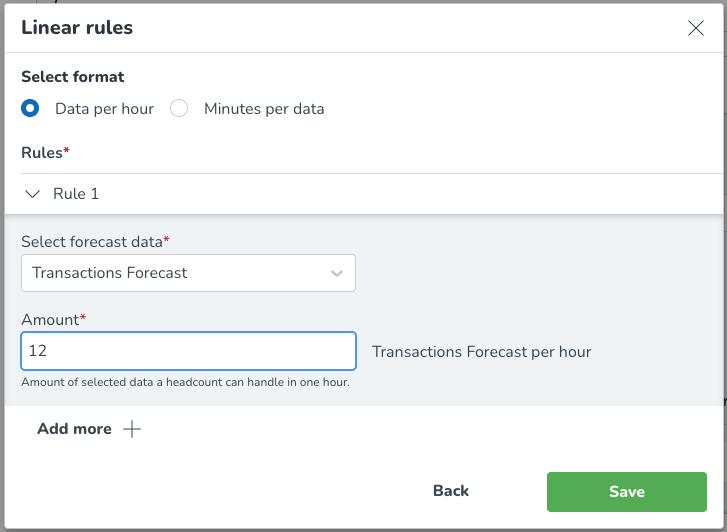
Du kan också lägga till flera konfigurationer till ett valt format. Detta gör du genom att välja Lägg till mer flera gånger efter att ha angett din initiala prognosdata och produktivitetsnivå. Nedan kan du se hur detta kommer att se ut på plattformen.
När du har lagt till mer än en konfiguration kommer du att kunna se dessa konfigurationer i en listvy som visas i bilden nedan.
Här kan du se dina arbetsregler som sparats.
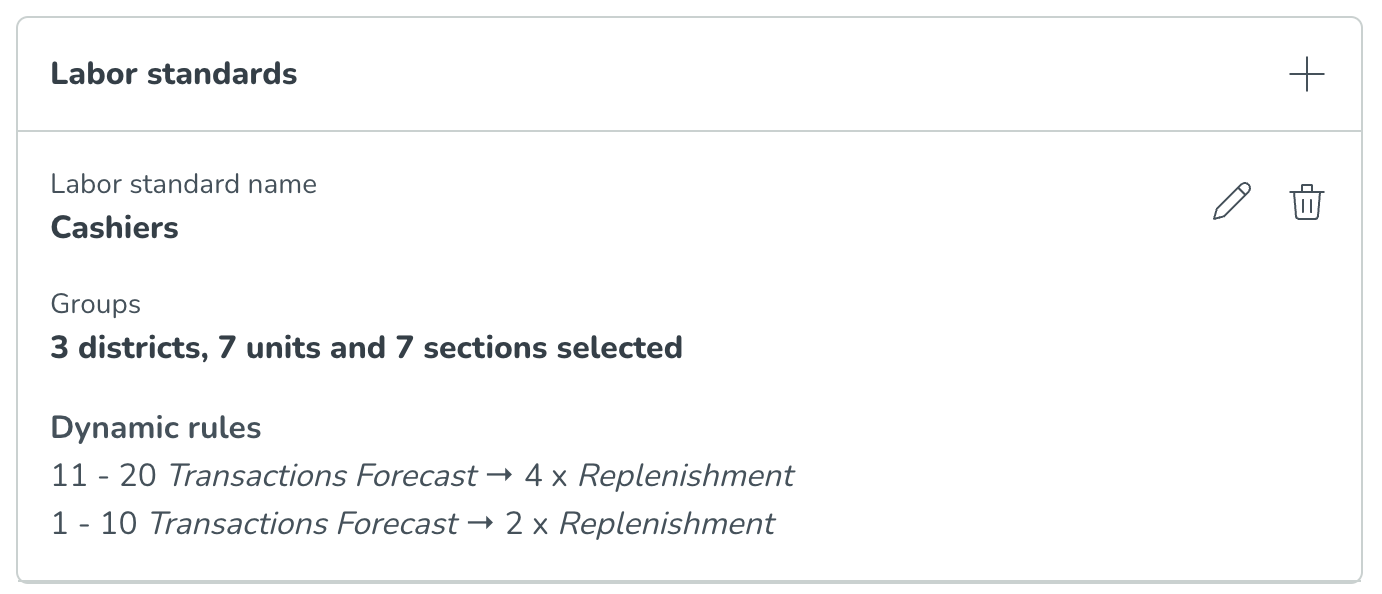
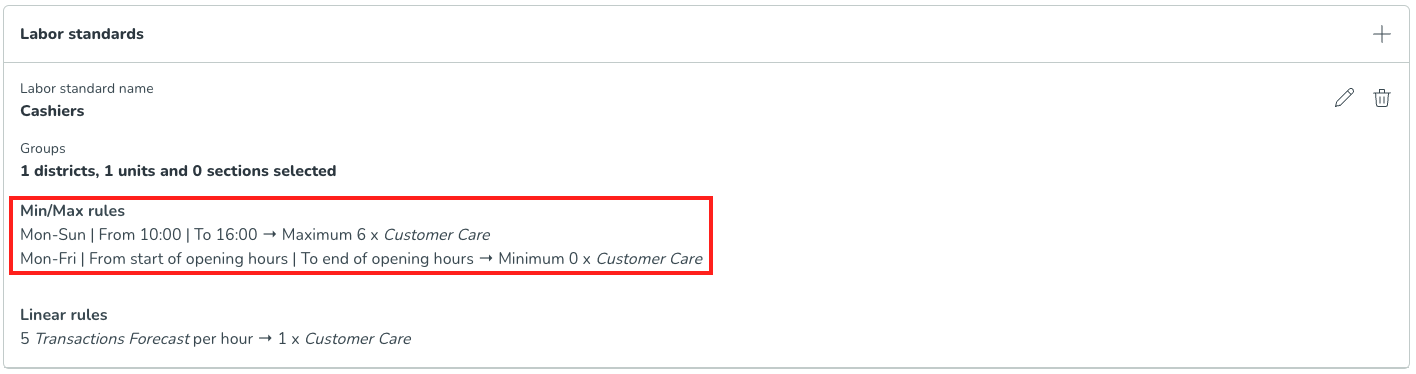
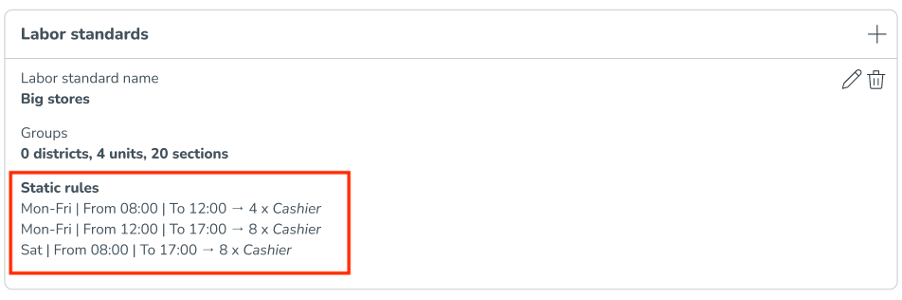
Nedan är vad du kommer att se när alla relevanta fält har fyllts i och arbetsstandarderna har sparats. Sammanfattningen av arbetsstandarderna möjliggör en enklare översikt över de konfigurerade arbetsreglerna och en indikation på hur många distrikt, enheter och avdelningar de tillämpas för.
Du kan också lägga till mer än en arbetsstandard, som visas i bilden nedan. Detta är relevant när olika grupper har olika produktivitetsnivåer och därför behöver konfigureras separat.
Om du har flera arbetsstandarder kommer du att kunna se sammanfattningen enligt följande.
Skapa arbetsstandarder med dynamiska regler
Dynamiska regler i arbetsstandarder kommer med tiden att ersätta de dynamiska regler som för närvarande kan konfigureras i gruppinställningar. Vänligen håll koll på Quinyx release notes för att få mer information när detta blir relevant. Om du vill konfigurera dina arbetsbehov för första gången, se till att använda dessa dynamiska regler och inte de i Gruppinställningar.
Vad är dynamiska regler?
Dynamiska regler är ett andra sätt, bredvid linjära regler, att definiera arbetskraftsbehov baserat på prognostiserade försäljningar/transaktioner/sålda varor osv. De kan konfigureras för din Optimala Bemanning individuellt eller kombineras med andra arbetsregler. Till skillnad från linjära regler tillåter dynamiska regler att du skapar en icke-linjär relation mellan dina prognosnivåer och dina bemanningsbehov. På så sätt kan du hantera scenarier där till exempel kassörer under hektiska perioder kan hantera en transaktion snabbare än under lugnare perioder.
Dynamiska regler är baserade på specificerade prognosintervall/buckets, vilket resulterar i fördefinierade bemanningsbehov. Till exempel, om jag har mellan 1-40 transaktioner inom en timme, skulle jag behöva schemalägga 2 kassörer. Jämfört med linjära regler kräver dynamiska regler inte genomsnittliga produktivitetsmått såsom genomsnittlig tid det tar för en kassör att hantera en transaktion.
Hur konfigurerar du dynamiska regler?
För att konfigurera minimum- och maximumregler måste du först följa stegen som nämns tidigare i den här artikeln kring skapande av din optimala bemanningsvariabel, samt att ange de initiala arbetsstandardreglerna. Du kan lägga till dina dynamiska regler i samma arbetsstandard som dina andra regler (t.ex. minimi- och maximiregler) eller så kan du skapa en annan arbetsstandard om dessa nya dynamiska regler är tillämpliga på en annan grupp.
När dina arbetsstandarder är skapade kan du lägga till dina specifika dynamiska regler.
Välj Lägg till arbetsregel
Välj Dynamiska regler
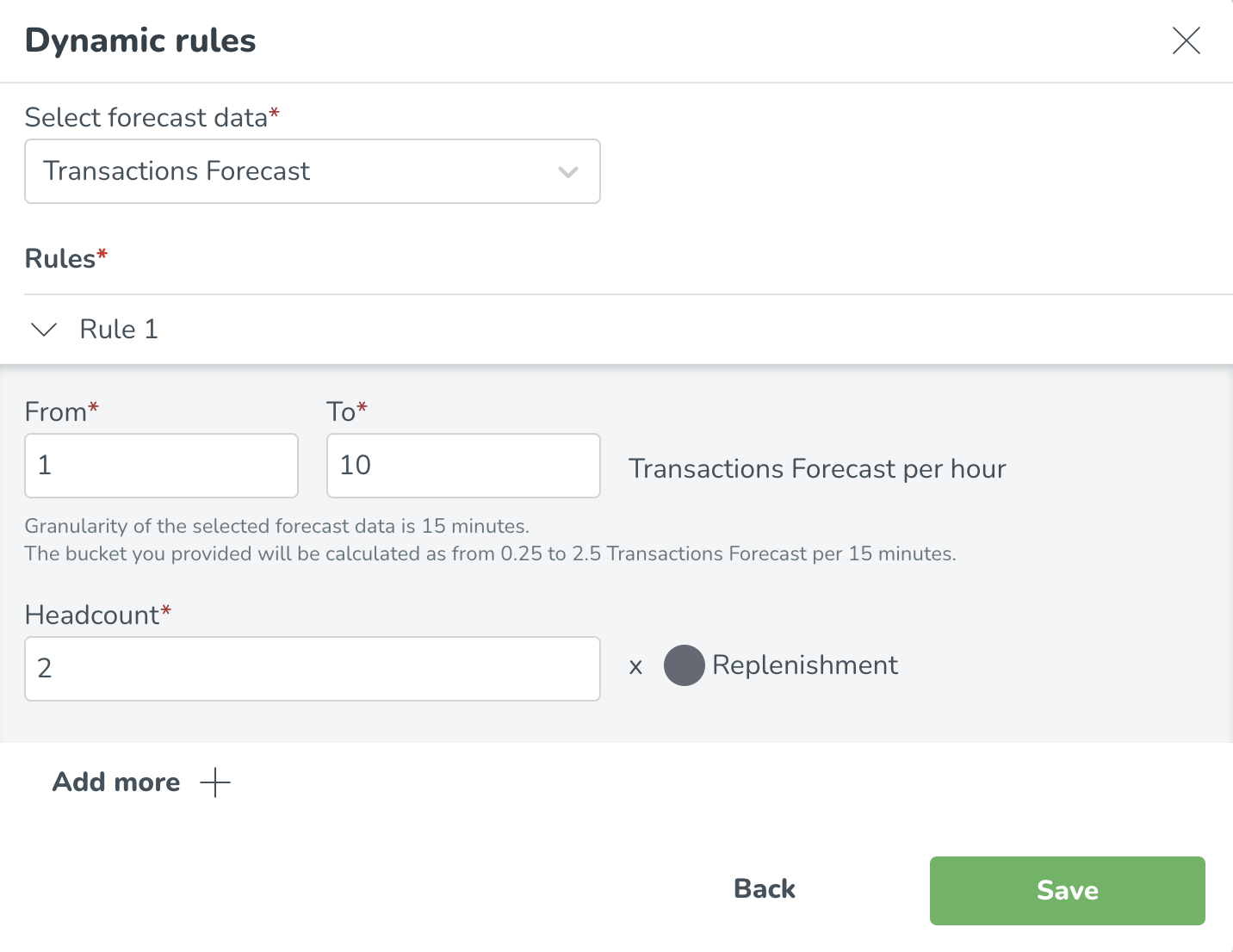
Välj prognosdata som den dynamiska regeln är baserad på
Ange de specifika dynamiska arbetsreglerna som är tillämpliga för din organisationLägg till flera prognosintervall/buckets genom att välja Lägg till fler.
När du är nöjd med de tillagda bucketsen, välj Spara. När alla regler är sparade kan du se de specifika dynamiska reglerna i sammanfattningen av arbetsstandarderna.
Begränsningar och överväganden vid tillägg av dynamiska regler
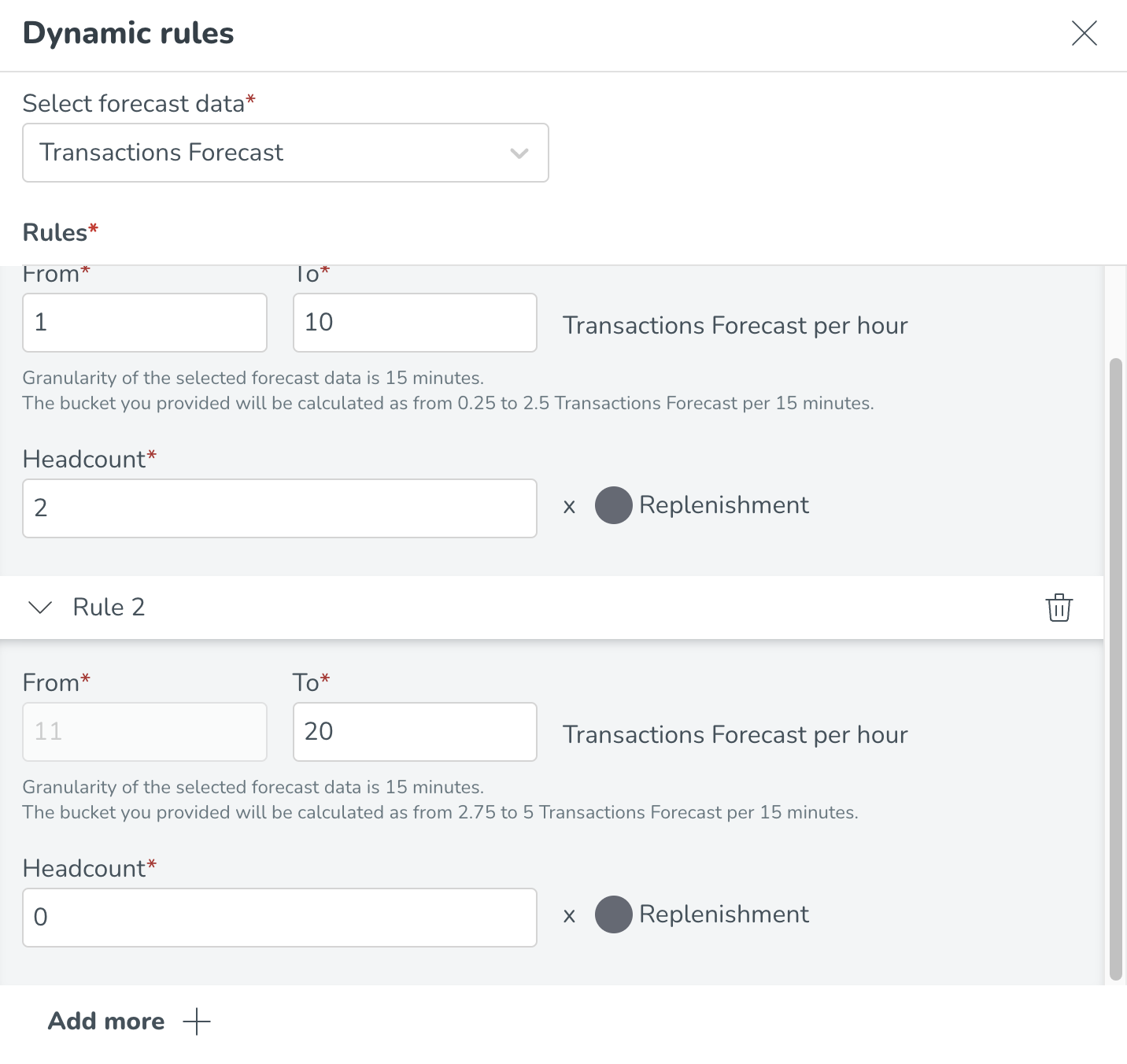
Du kan inte lägga till överlappande buckets.
Från-värdet för den efterföljande bucketen kommer alltid att ha nästa värde efter till-värdet för den föregående bucketen (t.ex. 1-10 transaktioner, 11-20 transaktioner).
Till-värdet för bucketen måste alltid vara större än från-värdet.
Eventuella prognosvärden som är större än det högsta värdet i den senaste bucketen kommer att resultera i ett noll bemanningsvärde, så se till att lägga till tillräckligt stora bucketar för att täcka alla möjliga prognosvärden.
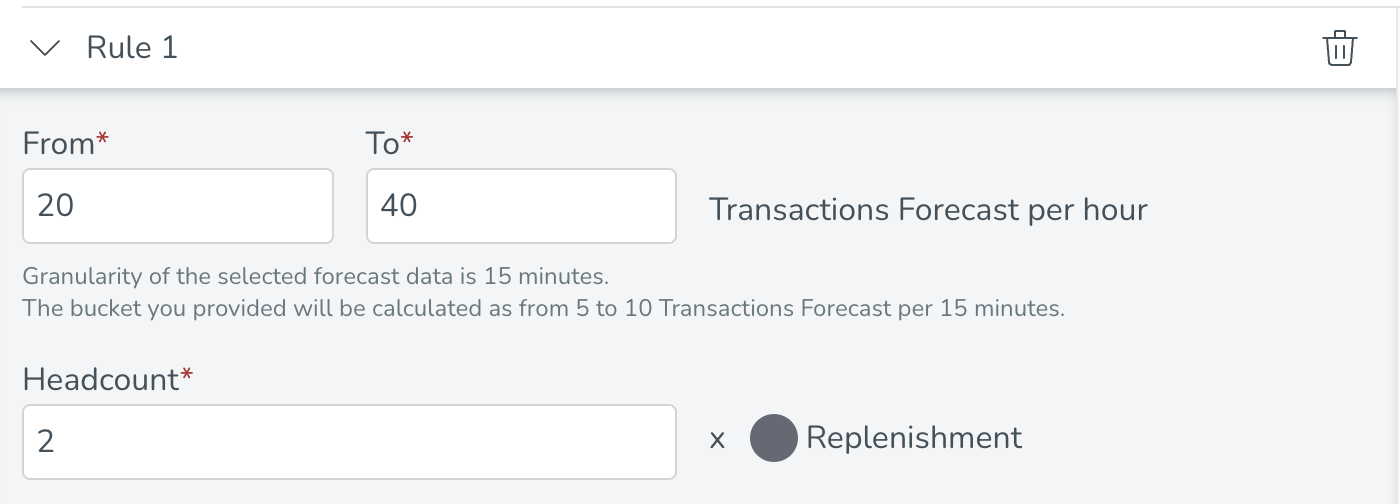
Datagranularitet: de dynamiska reglerna kan endast konfigureras på timbasis (t.ex. från 20 till 40 transaktioner per timme kräver 4 bemanning). Intervallen kommer automatiskt att omberäknas baserat på granulariteten i din valda prognosdata. Till exempel, om din prognosdata har en 15 minuters granularitet kommer vi att beräkna bucketen som från 50 till 10 transaktioner per 15 minuter kräver 4 bemanning. På så sätt kan vi korrekt relatera din dynamiska regelkonfiguration till din underliggande datagranularitet. Detta förklaras också i beskrivningstexten nedanför varje bucket (se skärmdump nedan).
Skapa arbetsstandarder med minimum/maximum regler
Vad är minimum- och maximumregler?
Minimum- och maximumregler är begränsningar som kan konfigureras för din optimala bemanning för att ange den minsta eller största bemanningen som behövs för den specifika rollen/skifttypen. Till exempel kan det vara så att du behöver se till att minst 1 chef är schemalagd hela tiden. Alternativt se till att du aldrig kan schemalägga mer än 6 kassörer samtidigt, även om efterfrågan kan kräva det på grund av enhetens fysiska begränsningar.
Minimum- och maxregler kan användas för informativa ändamål vid manuell schemaläggning eller för att begränsa Auto-schema för att säkerställa att det resulterande schemat inte överskrider de angivna minimi- eller maximikraven.
I framtida versioner planerar vi också att visualisera minimum- och maximumregler i visningsgruppen för arbete. Håll utkik i release notes!
Hur konfigurerar du minimum- och maximumregler?
För att konfigurera minimum- och maximumregler måste du först följa stegen som nämns tidigare i den här artikeln kring skapande av din optimala bemanningsvariabel och ange de initiala arbetsstandardreglerna. Du kan lägga till dina minimum- och maximumregler i samma arbetsstandard som dina andra regler (t.ex. linjära regler) eller så kan du skapa en annan arbetsstandard om dessa nya minimum- och maximumregler är tillämpliga på en annan grupp.
När dina arbetsstandarder är skapade kan du lägga till dina specifika minimum- och maximumregler.
Välj Lägg till arbetsregel
Välj Min/max-regel
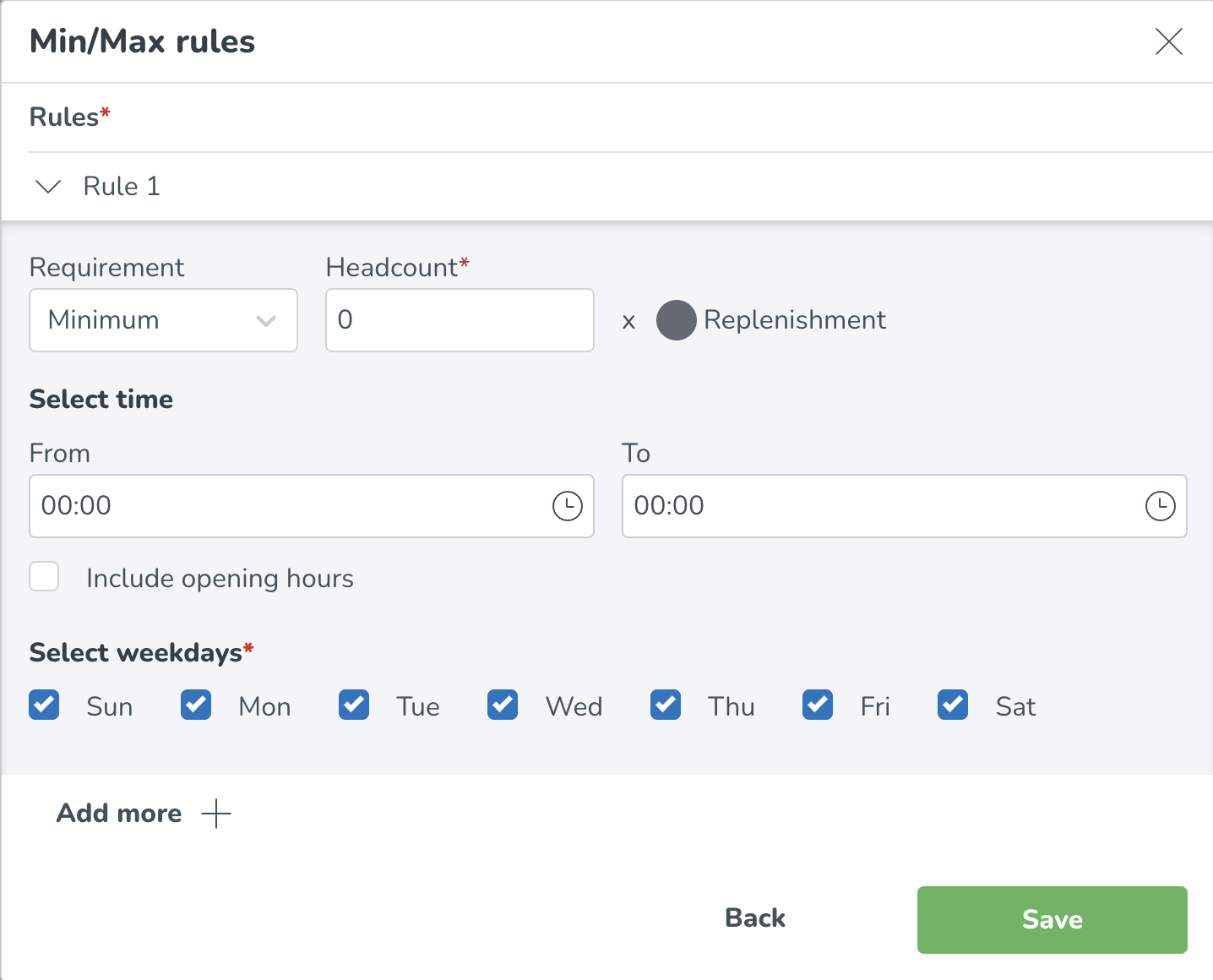
Välj om du lägger till en minimum- eller maximumregel i rullgardinsmenyn och ange det specifika minimi- eller maximikravet som gäller för den specifika rollen/skifttypen.
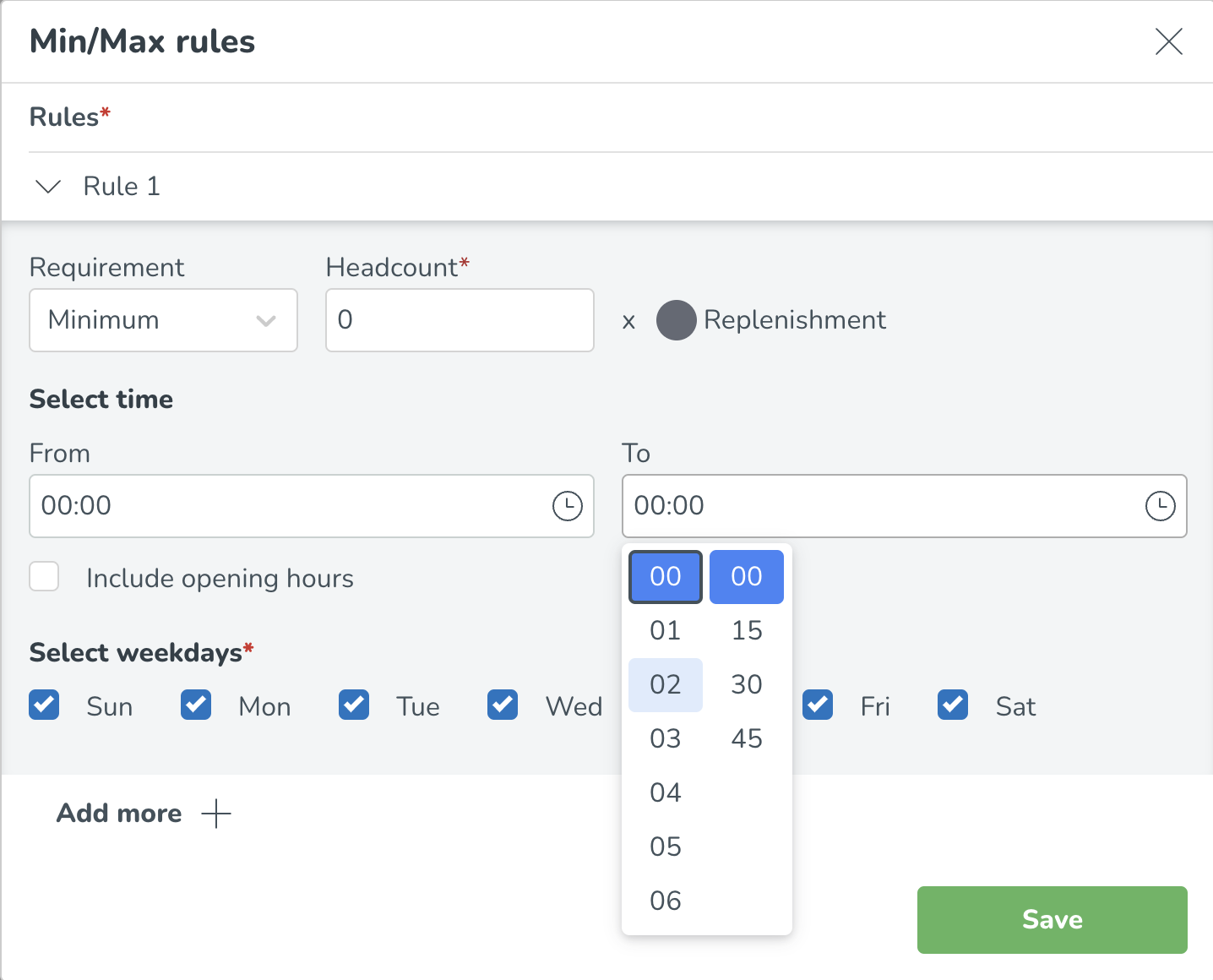
Minimum- och maximumregler kan konfigureras per tid på dagen. Detta kan göras genom att ange eller välja specifika tidsramar på en 15 min nivå.
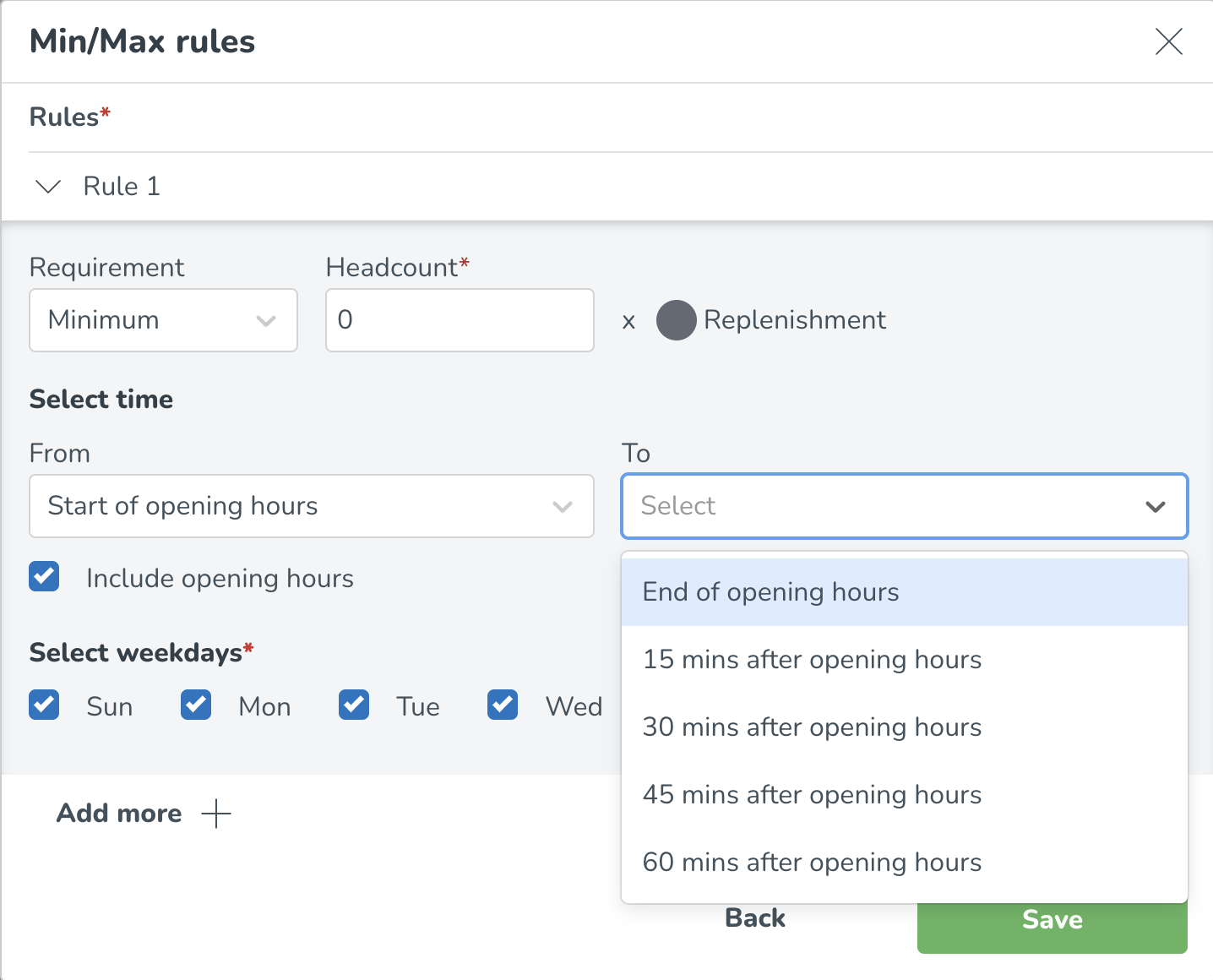
Det är också möjligt att koppla min- och maxreglerna till dina öppettider, t.ex. om du behöver minst 1 chef 15 minuter före öppettiderna till 15 minuter efter öppettiderna. Läs mer om hur du ställer in dina öppettider här: Öppettider - standard och specialtider.
Min/max-regler baserade på öppettider kan konfigureras genom att välja alternativet Inkludera öppettider och ange de relativa kraven till öppettiderna.
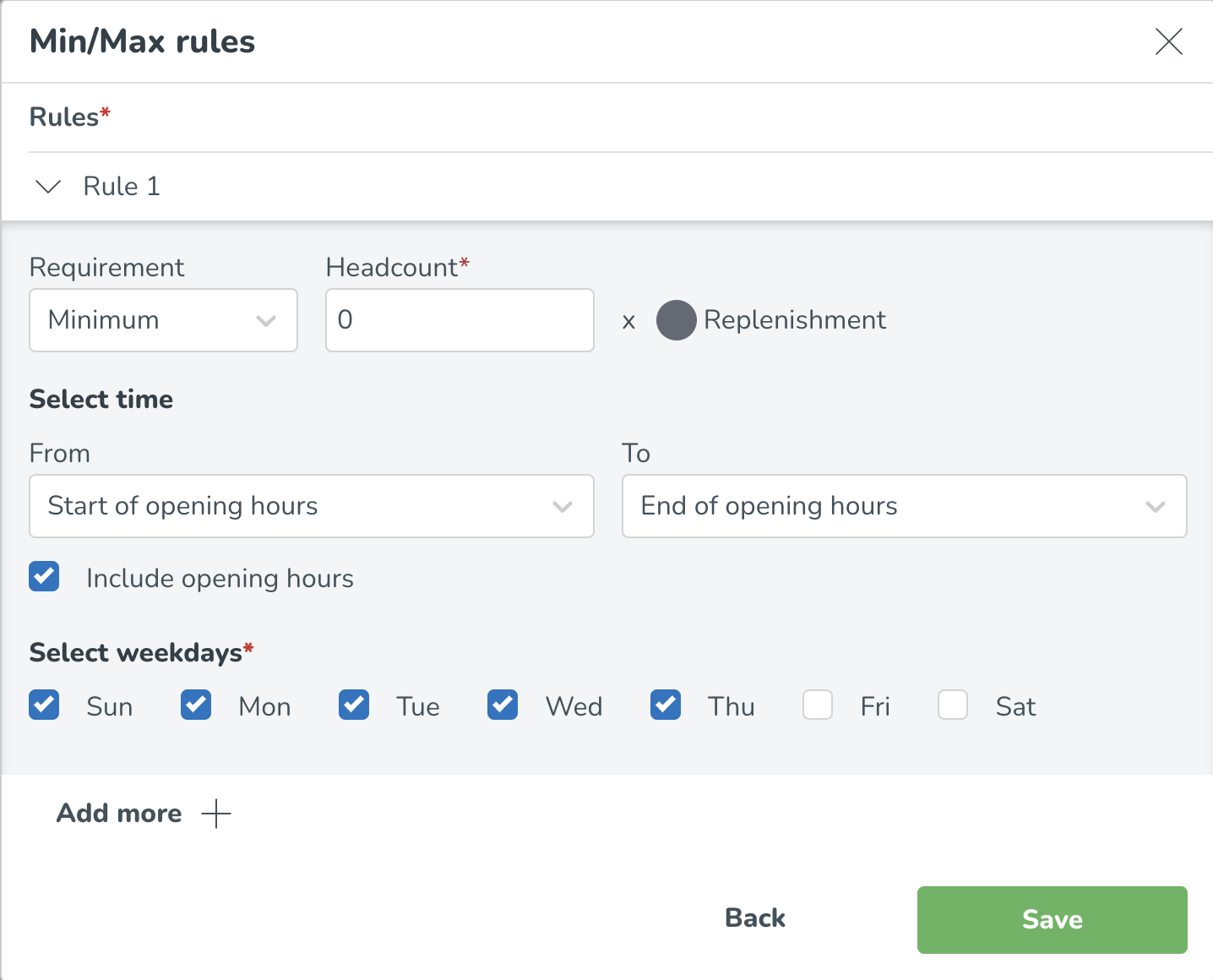
Min- och maxregler kan också konfigureras per veckodag. Genom att välja/avvälja specifika veckodagar inom avsnittet Välj veckodagar* kan du välja vilka dagar dessa specifika regler är tillämpliga.
Lägg till ytterligare regler genom att välja Lägg till fler, och lägg till eventuella ytterligare min- eller maxregler baserat på tid på dagen och veckodag.
När alla regler är sparade kan du se de specifika min- och maxreglerna i sammanfattningen av arbetsstandarder.
Begränsningar för minimum- och maximumregler
Du kan inte lägga till motstridiga minimum- och maximumregler.
Om du lägger till flera minimum- eller maximumregler för samma tidsperiod och samma dag kommer Quinyx att använda den strängaste regeln (dvs det högsta minimumkravet och det lägsta maximumkravet).
Skapande av arbetsnormer med statiska regler
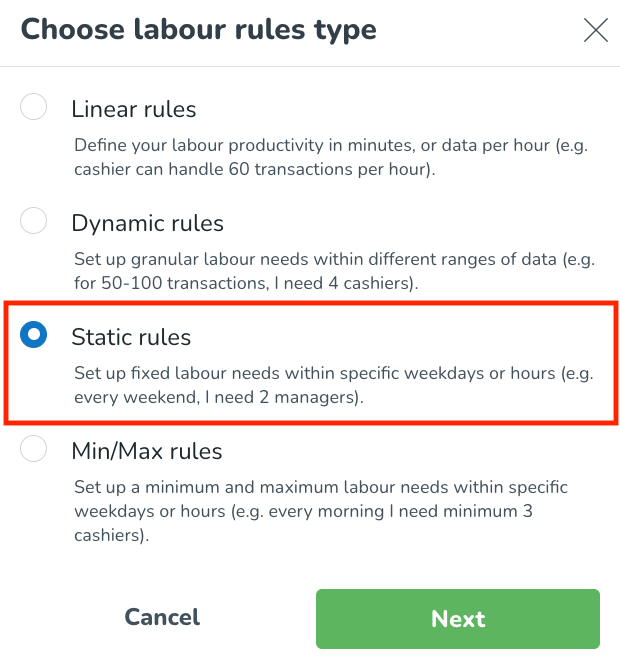
Vad är statiska regler?
Statiska regler är ett annat sätt att definiera arbetskraftsbehov. Statiska regler är en begränsning som kan konfigureras för ditt optimala antal anställda för att ange det antal anställda som behövs eftersom det är ett fast och upprepande krav. Du kan till exempel alltid behöva ha en chef schemalagd hela tiden under dina öppettider.
Hur konfigurerar jag statiska regler?
För att konfigurera statiska regler måste du först följa stegen som nämns tidigare i den här artikeln om att skapa din optimala variabel för antal anställda och ange de första arbetsstandardreglerna. Du kan lägga till dina statiska regler i samma arbetsstandard som dina andra regler (t.ex. linjära regler) eller skapa en annan arbetsstandard om dessa statiska regler gäller för en annan grupp.
När dina arbetsstandarder har skapats kan du lägga till dina specifika statiska regler.
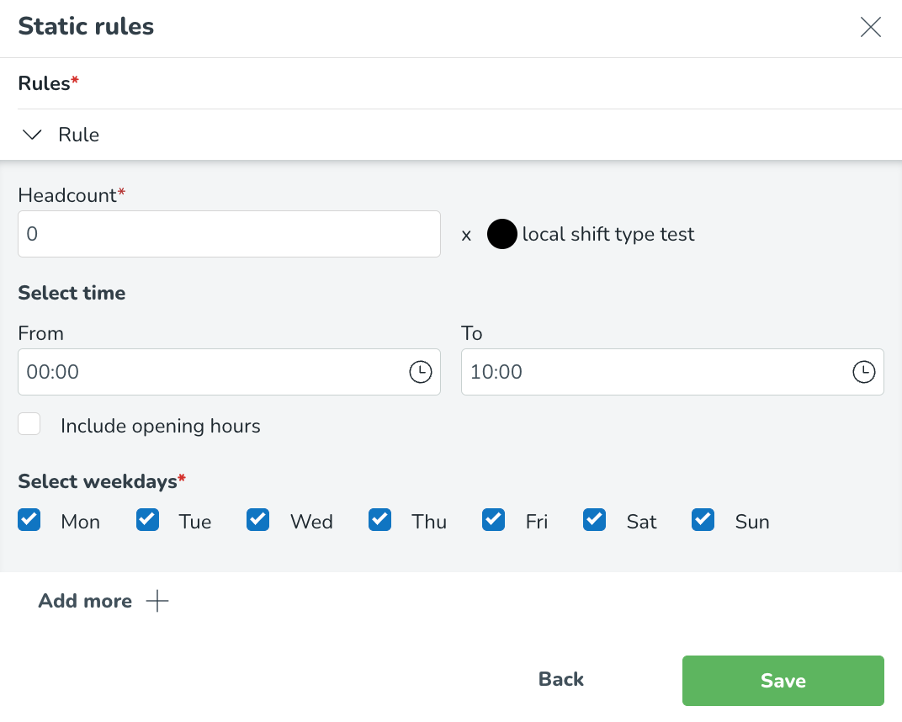
Välj Lägg till arbetsregel knappen.
Välj Statiska regler knappen.
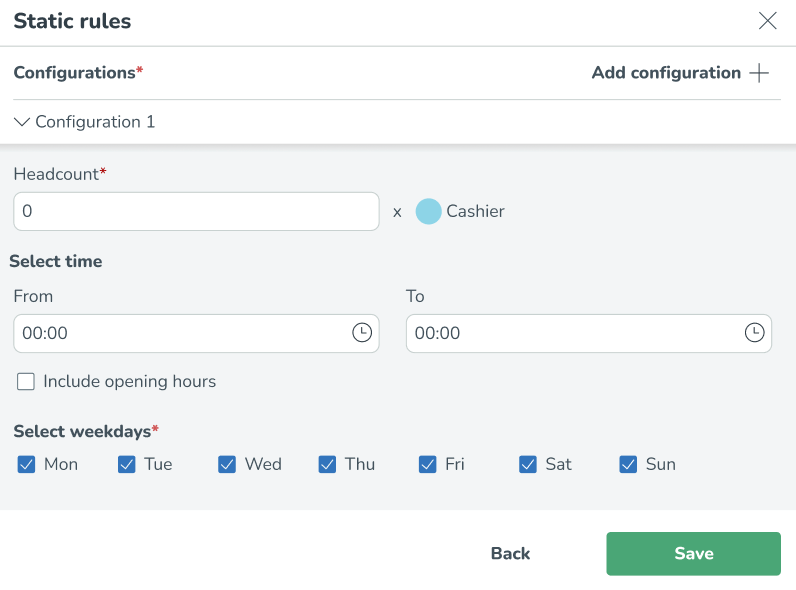
Ange det antal personer som krävs och ange de specifika timmar som du vill att regeln ska gälla för.
Statiska regler kan konfigureras per tid på dygnet. Detta kan göras genom att ange eller välja specifika tidsramar på en 15-minuters nivå.
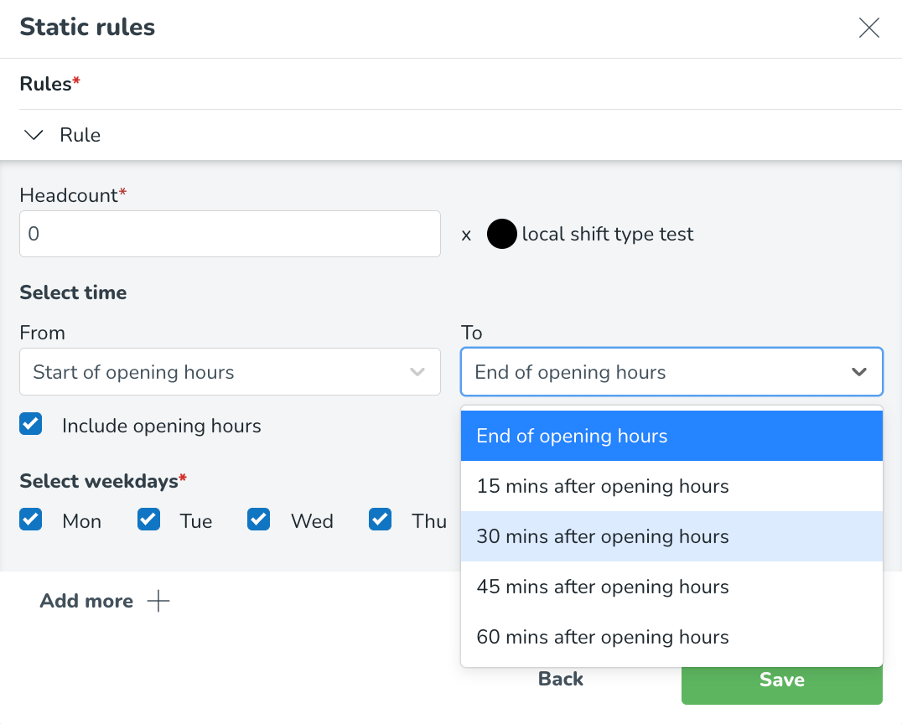
Det är också möjligt att koppla de statiska reglerna till dina öppettider. Till exempel behöver du en viss chef 15 minuter före öppettiderna till 15 minuter efter öppettiderna på plats. Läs mer om hur du ställer in dina öppettider här: Öppettider - ordinarie och avvikande öppettider.
Statiska regler baserade på öppettider kan konfigureras genom att välja alternativet Inkludera öppettider och ange de relativa kraven för öppettiderna.
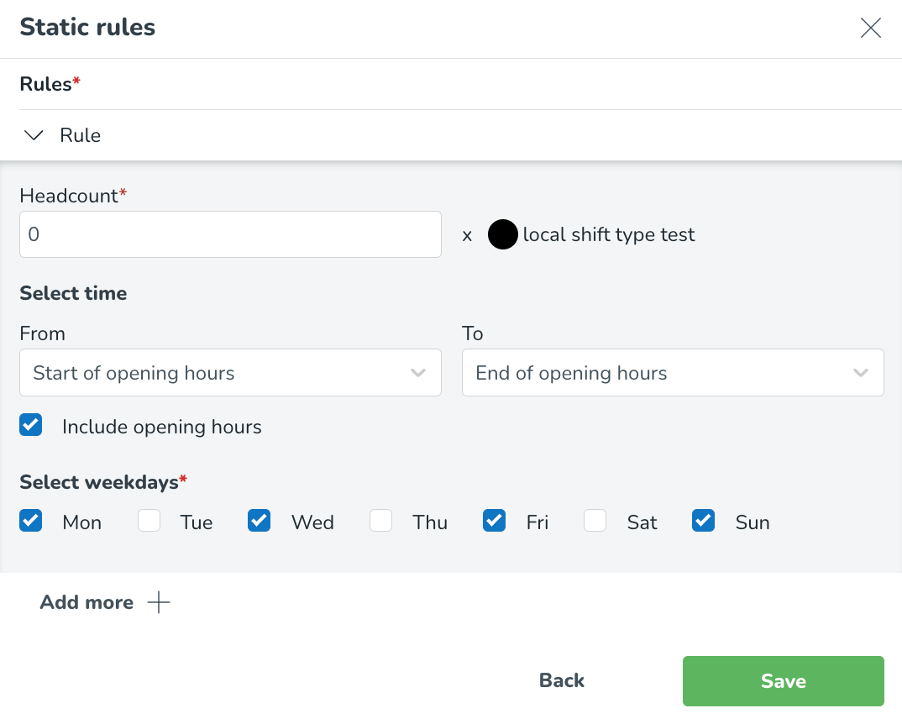
Statiska regler kan också konfigureras per veckodag. Du kan välja vilka dagar dessa regler ska gälla genom att markera/avmarkera specifika veckodagar inom Välj veckodagar* sektionen.
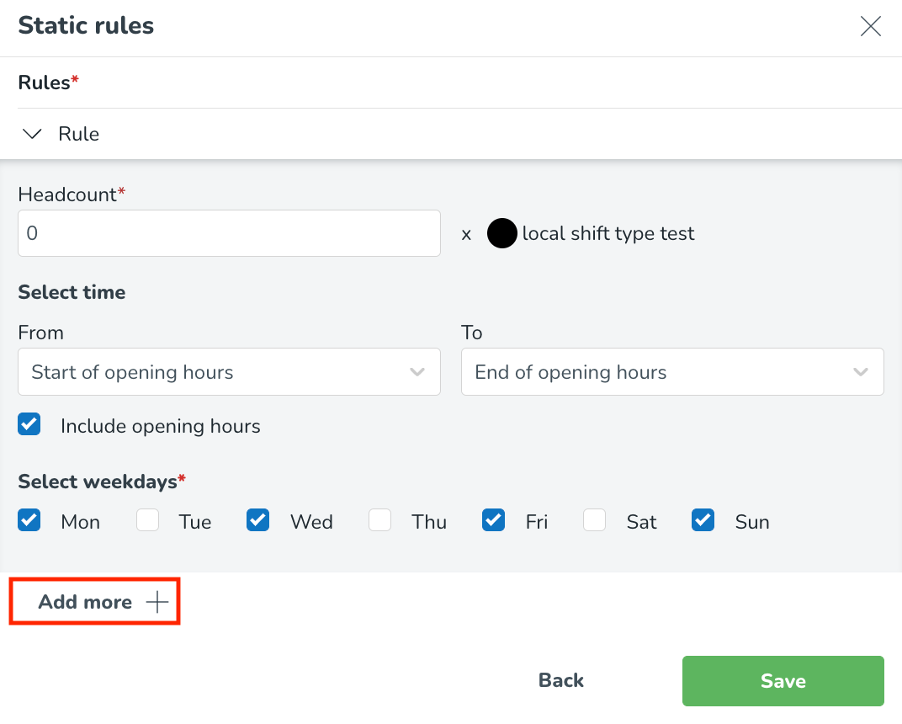
Lägg till ytterligare regler genom att välja Lägg till knappen och lägg till eventuella statiska regler baserade på tid på dygnet och veckodag.
När alla regler har sparats kan du se de specifika statiska reglerna i sammanfattningen av arbetsnormer.
Om du till exempel ställer in en statisk regel på 15-minutersnivå (du behöver 1 person från 14.45 till 15.00) samt har en linjär regel på 60-minutersnivå, kommer den regel som har lägst detaljnivå att väljas i den optimala headcounten.
Radera arbetsstandarden
Det finns tre nivåer av att radera arbetsstandarder.
Att radera den optimala bemanningsvariabeln skulle radera alla underliggande arbetsstandarder och ta bort variabeln från alla visningsgrupper. Detta kan göras på sidan för variabelinställningar.
Att radera arbetsstandarder inom den optimala bemanningsvariabeln kan göras genom att välja papperskorgen bredvid den relevanta arbetsstandarden. Detta kommer att ta bort arbetsreglerna för de specifika grupperna som valts i arbetsstandardkonfigurationen.
Att radera specifika regler inom en specifik arbetsstandard kan göras genom att välja papperskorgen när du redigerar arbetsstandarden. Detta kommer att ta bort den specifika arbetsregeln från arbetsstandarden. Om en arbetsregel är konfigurerad baserat på en prognoskonfiguration (t.ex. transaktioner) och prognoskonfigurationen raderas, kommer arbetsreglerna baserade på den raderade prognoskonfigurationen också att tas bort. Arbetsregler baserade på andra prognoskonfigurationer som inte har raderats kommer inte att tas bort.
Beräkning av Optimal Bemanning baserat på Arbetsstandarder
När de optimala bemanningsvariablerna med de definierade arbetsnormerna och linjära arbetsregler har sparats, kommer den variabeln att synas på sidan för variabelinställningar. Nästa steg är att lägga till bemanningsvariablerna i eventuella ytterligare visningsgrupper, förutom arbetsvisningsgruppen, och lägga till synlighet på schema- och prognossidan.
Den optimala bemanningen för den optimala bemanningsvariabeln kommer att beräknas baserat på den relevanta prognosen och de definierade arbetsreglerna. När några ändringar görs i prognosen eller arbetsreglerna kommer ändringarna omedelbart att tillämpas, och den optimala bemanningen kommer att räknas om.
Visualisering av Optimal Bemanning - Arbetsvisningsgrupp
Visualisering av bemanningen av Optimal Bemanning & Arbetsstandarder -funktionaliteten fångas av den standardiserade visningsgruppen: Arbete.
Arbete-visningsgruppen kommer automatiskt att skapas när en optimal bemanningsvariabel skapas genom Optimal Bemanning & Arbetsstandarder - NY funktionaliteten. Den optimala bemanningsvariabeln, liksom eventuellt skapade optimala bemanningsvariabler, kommer automatiskt att läggas till i den nyss skapade visningsgruppen Arbete med synlighet både i Schema och Prognos. Du kan självklart ändra synligheten för variablerna senare.
Visningsgrupp för arbete- Graf
Filtreringsmöjligheterna och jämförelsen med schemalagd bemanning är endast möjliga i schemastatistiken, ännu inte i prognosgrafen och tabellen. I prognosgrafen och tabellen kan du endast se de individuella optimala bemanningsvariablerna i den nya visningsgruppen.
I visningsgruppen Arbete kan du se total optimal bemanning, vilket är en summering av alla optimala bemanningsvariabler i enheten du tittar på, samt optimal bemanning per varje individuell optimal bemanningsvariabel genom vår filtreringsmöjlighet som endast är tillgänglig för visningsgruppen Arbete.
Som standard kommer du att se den totala optimala bemanningen.
Genom att använda filtreringsfunktionaliteten kan du välja att endast se den optimala bemanningen för exempelvis kassören bemanningVariabel.
Med hjälp av filtreringsfunktionen kan du välja att visa den optimala bemanningen endast för t.ex. variabeln antal anställdai kassan.
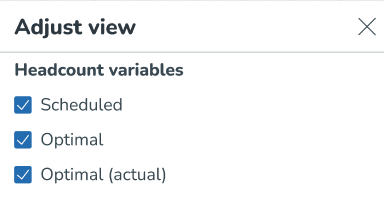
Du kan också jämföra optimalt antal anställda med schemalagt antal anställda totalt, automatiskt schemalagt antal anställda, faktiskt optimalt antal anställda samt per variabel för optimalt antal anställda. Detta hjälper dig att verifiera om du har schemalagt tillräckligt med personal för att matcha det antal anställda som krävs för att möjliggöra en mer exakt schemaläggning. Detta kan göras genom att se till att både Schemalagd och Optimal är markerade i panelen Anpassa vy.
Du kan också använda variabeln Auto-Scheduled om du använder funktionen Auto-Schedule för att automatiskt skapa skift för dina anställda. Det automatiskt schemalagda antalet anställda är jämförbart med det schemalagda antalet anställda och ditt optimala antal anställda. Det gör det möjligt för dig att förstå hur många manuella ändringar som gjordes i schemat efter att det automatiska schemat skapades och om det befintliga schemat eller det automatiskt skapade schemat är mer exakt jämfört med det optimala antalet anställda.
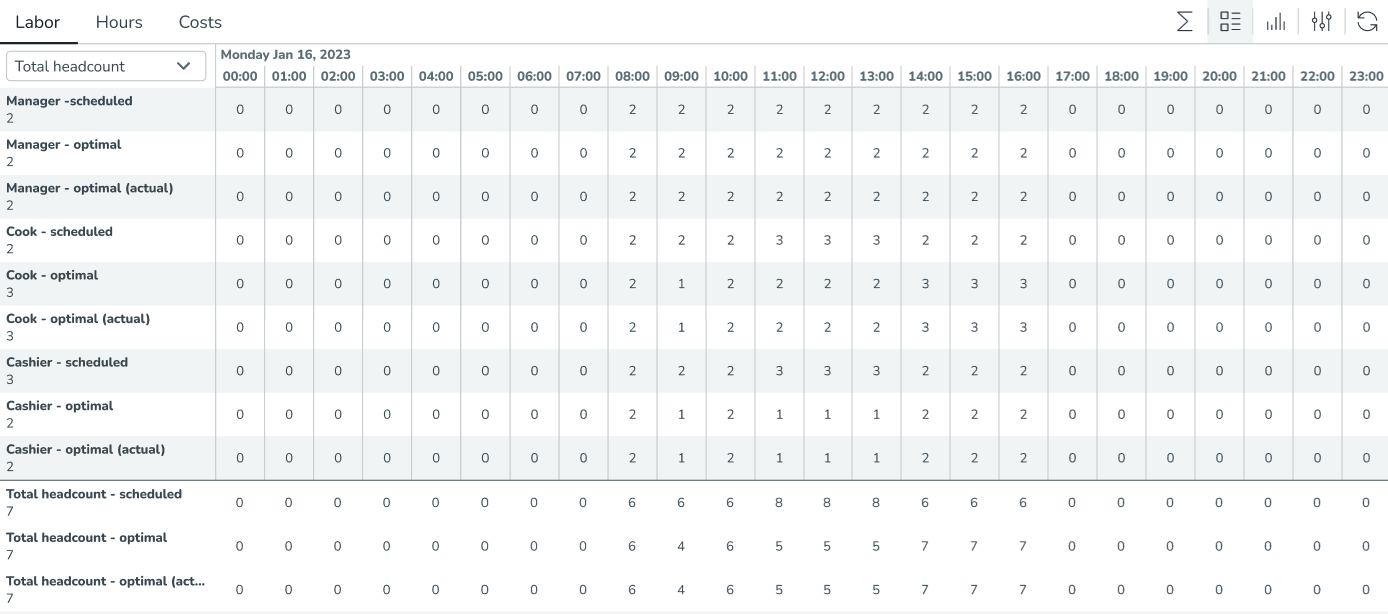
I diagrammet representeras det schemalagda antalet anställda av den ljusblå linjen, det optimala antalet anställda av den mörkgröna bakgrunden, det faktiska optimala antalet anställda av den lila linjen och det automatiskt schemalagda antalet anställda av den orange bakgrunden.
Observera att auto-scheduled variabeln endast är synlig i schemavyn under visningsgruppen Arbete.
Du kan också jämföra optimal bemanning baserat på prognosdata med optimal bemanning baserat på faktiska data totalt sett, samt för varje optimal bemanning variabel. Detta hjälper dig att verifiera skillnaden mellan optimal bemanning baserat på prognosdata ("hur många personer ska jag schemalägga baserat på min prognos?"), optimal bemanning baserat på faktiska data ("hur många personer borde jag ha schemalagt baserat på mina faktiska nivåer?") gentemot schemalagd bemanning. Skillnader i dessa två variabler skulle indikera potentiella prognos- eller arbetsstandardproblem.
Den optimala (aktuella) bemanningskurvan är endast synlig i det förflutna, där faktiska data är tillgängliga.
I grafen representeras den schemalagda bemanningen av linjen med skuggad bakgrund, medan den optimala (prognostiserade) bemanningen representeras av den mörkblå linjen. Den lila linjen representerar den optimala (aktuella) bemanningen.
Du kan välja vilka bemanningsvariabler du är intresserad av att se inom justeringsvy panelen.
Medan den optimala bemanningen beräknas baserat på de beräkningsregler som är konfigurerade för den specifika variabeln och den specifika enheten i Optimal Bemanning & Arbetsstandarder - NY konfigurationen, beräknas den schemalagda bemanningen baserat på antalet skift som är schemalagda med skifttypen som matchar den konfigurerade skifttypen på den optimala bemanningsvariabeln i variabelinställningar. Endast en skifttyp kan väljas per optimal bemanningsvariabel.
I prognos fliken visualiserar vi för närvarande endast den optimala bemanningen per varje optimal bemanningsvariabel utan möjligheten till filtrering och visualisering av schemalagd bemanning.
Visningsgrupp för arbete - Tabell
Den optimala prognosen, optimal faktisk, och schemalagd bemanning kan också ses i tabellvyn. När Total bemanning är vald, visualiserar Quinyx varje optimal bemanningsvariabel separat, vilket visar optimal och bemanning.
Genom att scrolla till botten av tabellen summerar Quinyx den totala optimala och schemalagda bemanningen om alla variabler har valts Anpassa vy-panelen.
Genom att filtrera efter optimal bemanningsvariabel, eller genom att avmarkera antingen optimal eller schemalagd i Justeringsvyn panelen, kan du anpassa tabellen och endast se data som du är intresserad av.
Frågor och svar
Kan jag hantera arbetsstandarder via API?
Vi har gjort det möjligt att skapa, redigera och ta bort arbetsstandarder via API, vilket gör uppdateringar snabbare och skalbara.
För att aktivera detta, konfigurera helt enkelt ett External ID på din optimal bemanning-post — detta fungerar som länken som möjliggör API-integration. External ID bör vara max 160 tecken långt, och inga specialtecken eller mellanslag stöds.
När External ID är konfigurerat kan arbetsstandarderna skickas via vår offentliga endpoint. Detaljer om endpoint förklaras här: Swagger UI.
Arbetsstandarder som skickas till Quinyx via API kommer att vara synliga i gränssnittet, på samma sätt som de som konfigurerats manuellt.
Denna uppdatering ger operations- och integrationsteam flexibiliteten att antingen hantera arbetsstandarder manuellt i Quinyx, eller underhålla dem i ett externt system och automatiskt skicka uppdateringar till Quinyx via API.
Vad kommer att arbetas med härnäst inom den nya Optimala Bemanningen & Arbetsstandarderna funktionaliteten?
Med planen att fullt ut kunna ersätta den nuvarande statiska och dynamiska regel konfigurationen samt Pythia (AI-Optimering) arbetsstandardberäkningar, kommer vi att fortsätta utveckla ytterligare sätt att definiera arbetskraftsbehov för att möjliggöra mer omfattande arbetsstandarddefinitioner. Detta inkluderar att migrera funktionaliteter från nuvarande statiska och dynamiska regler, samt arbetsregler i Pythia (AI-Optimering). Håll er uppdaterade!
Vad behöver jag göra om jag för närvarande använder statiska och dynamiska regler för att definiera mina arbetskraftsbehov?
Ingenting ännu. Över tiden kommer vi att flytta över funktionaliteter från statiska och dynamiska regler, där du till slut kommer att behöva övergå till att använda de nya statiska och dynamiska funktionaliteterna. Mer information kommer. Tills dess kan du definiera och fortsätta använda dina arbetskraftsbehov genom nuvarande statiska och dynamiska regler samt de nya arbetsstandarderna.
Vad behöver jag göra om jag för närvarande använder Labour Standard Calculations i Pythia för att definiera mina arbetskraftsbehov?
Om du använder Auto-schema för att skapa dina scheman måste du vänta tills algoritmen kan ta hänsyn till dessa nya optimala bemanningsvärden som inmatning för att korrekt använda denna funktionalitet. Tills dess kan du konfigurera dina arbetskraftsbehov i Quinyx, men de kommer ännu inte att beaktas inom vår Auto-schema-lösning. Vänligen håll dig uppdaterad om när och hur detta kommer att vara möjligt.
 Uppdaterad
av
Leigh Hutchens
Uppdaterad
av
Leigh Hutchens
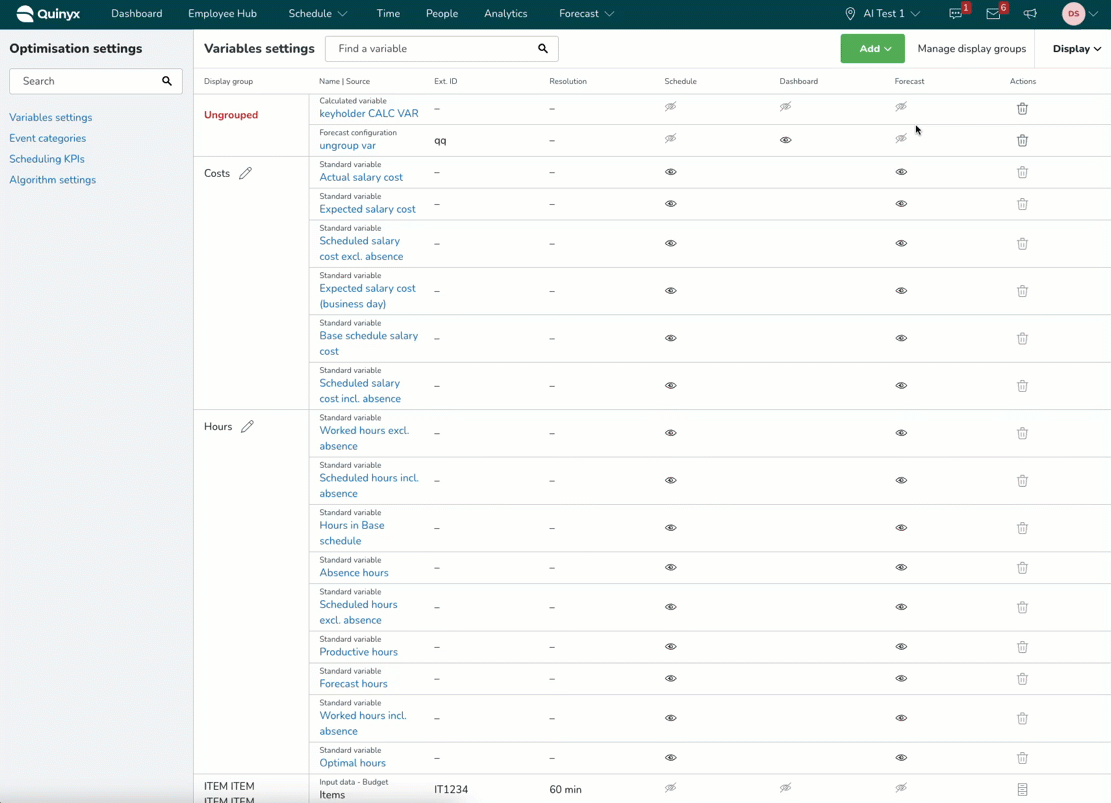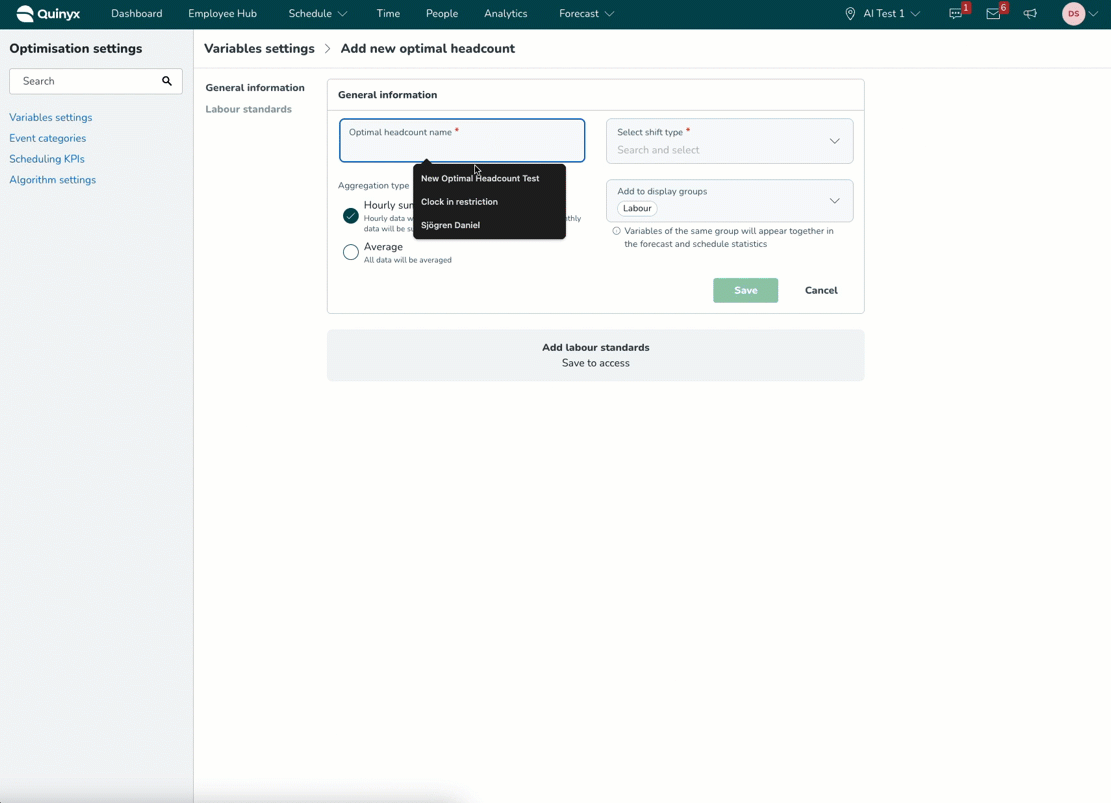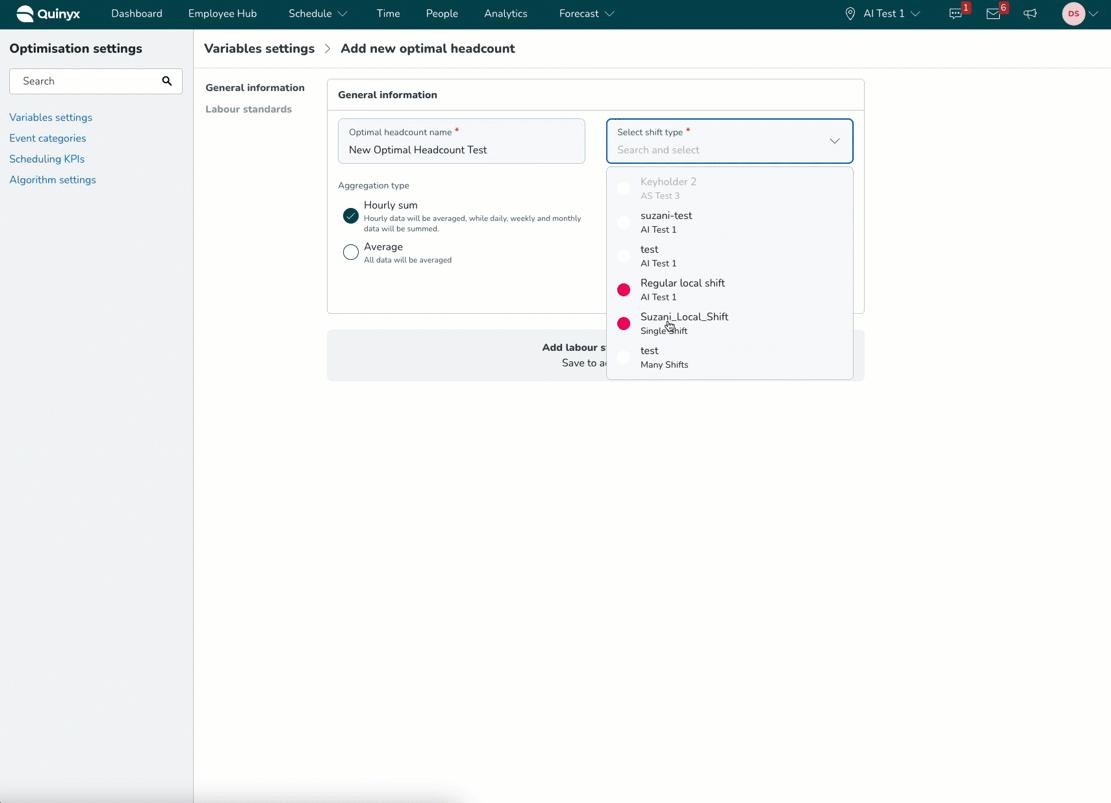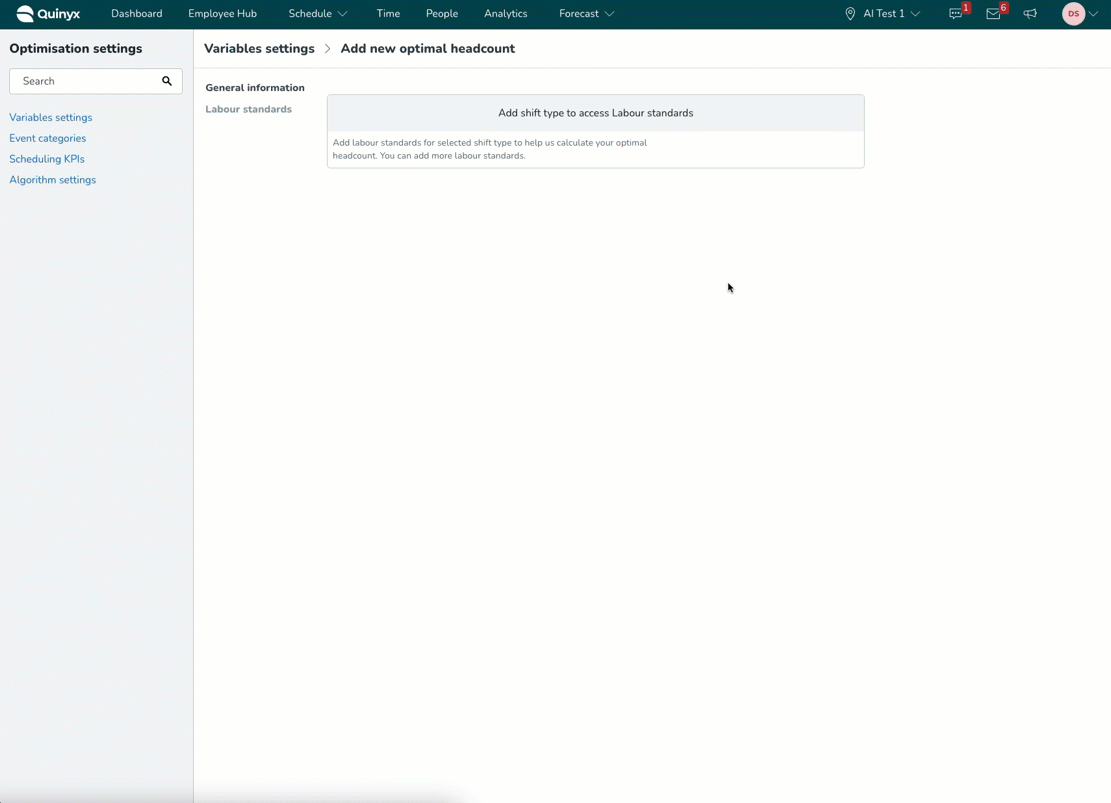
 När du skapar optimal bemanning baserat på lokala skifttyper kommer endast enheter och avdelningar som de lokala skifttyperna är relaterade till att returneras till gruppträdet vid konfigurering av arbetsstandarder. Namnet på enheten/avdelningen visas bredvid namnet på den lokala skifttypen. Detta säkerställer att inga enheter kan väljas där de lokala skifttyperna inte existerar, och det blir tydligare vilka specifika enheter de lokala skifttyperna tillhör.
När du skapar optimal bemanning baserat på lokala skifttyper kommer endast enheter och avdelningar som de lokala skifttyperna är relaterade till att returneras till gruppträdet vid konfigurering av arbetsstandarder. Namnet på enheten/avdelningen visas bredvid namnet på den lokala skifttypen. Detta säkerställer att inga enheter kan väljas där de lokala skifttyperna inte existerar, och det blir tydligare vilka specifika enheter de lokala skifttyperna tillhör.