Variabelinställningar, Visningsgrupper & Prognoskonfigurationer
 Uppdaterad
av
Daniel Sjögren
Uppdaterad
av
Daniel Sjögren
På sidan för variabelinställningar kan du skapa och hantera dina prognoskonfigurationer och variabelvisningsalternativ, inklusive att lägga till dem i visningsgrupper. Visningsgrupper påverkar hur variabler visualiseras i schemas statistiken och fliken Prognos.
Navigera till Optimeringsinställningar > Variabler > Variabelinställningar för att visa en översikt över alla dina konfigurationer, beräknade och standardvariabler, och var de för närvarande visas.
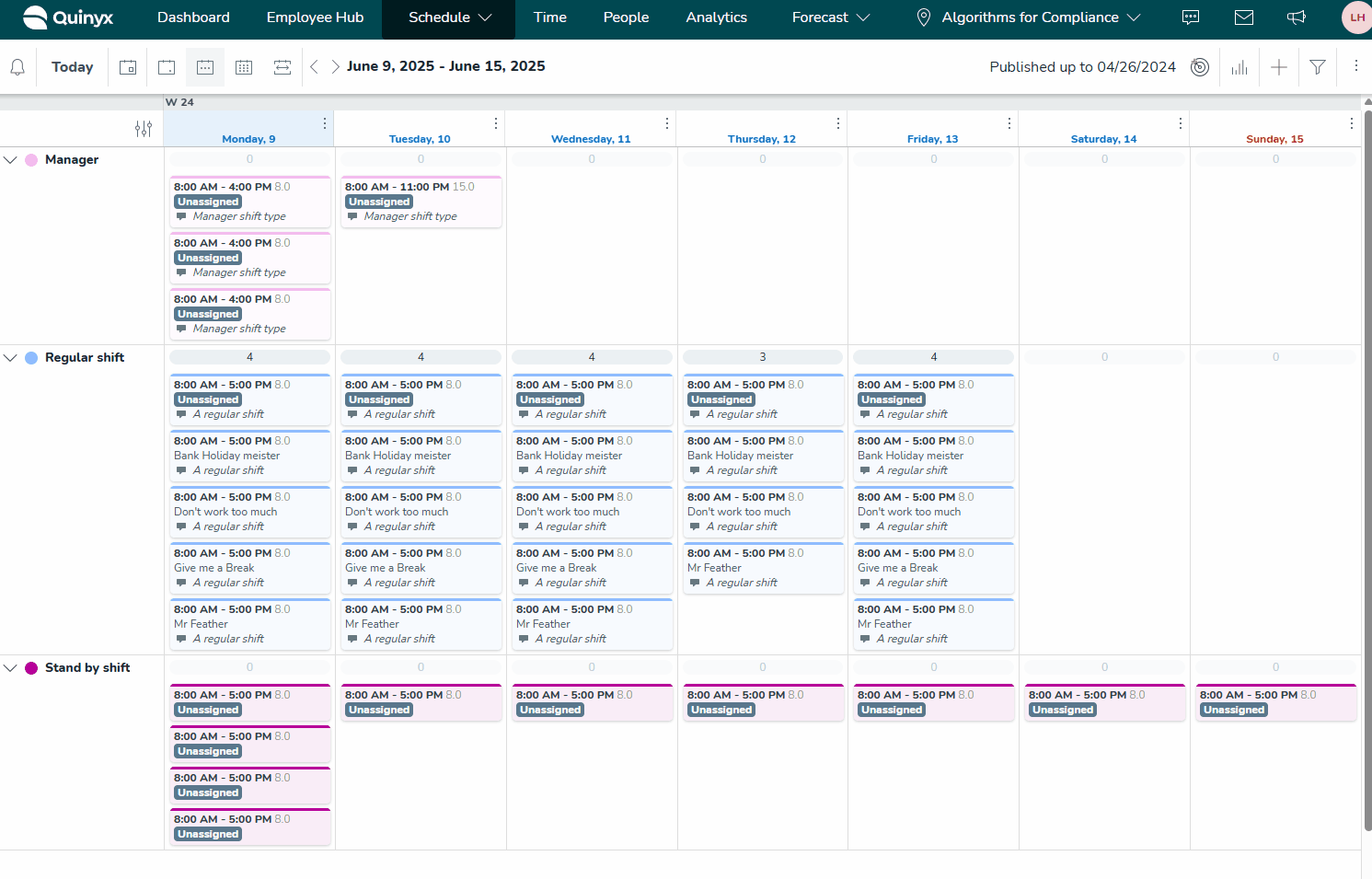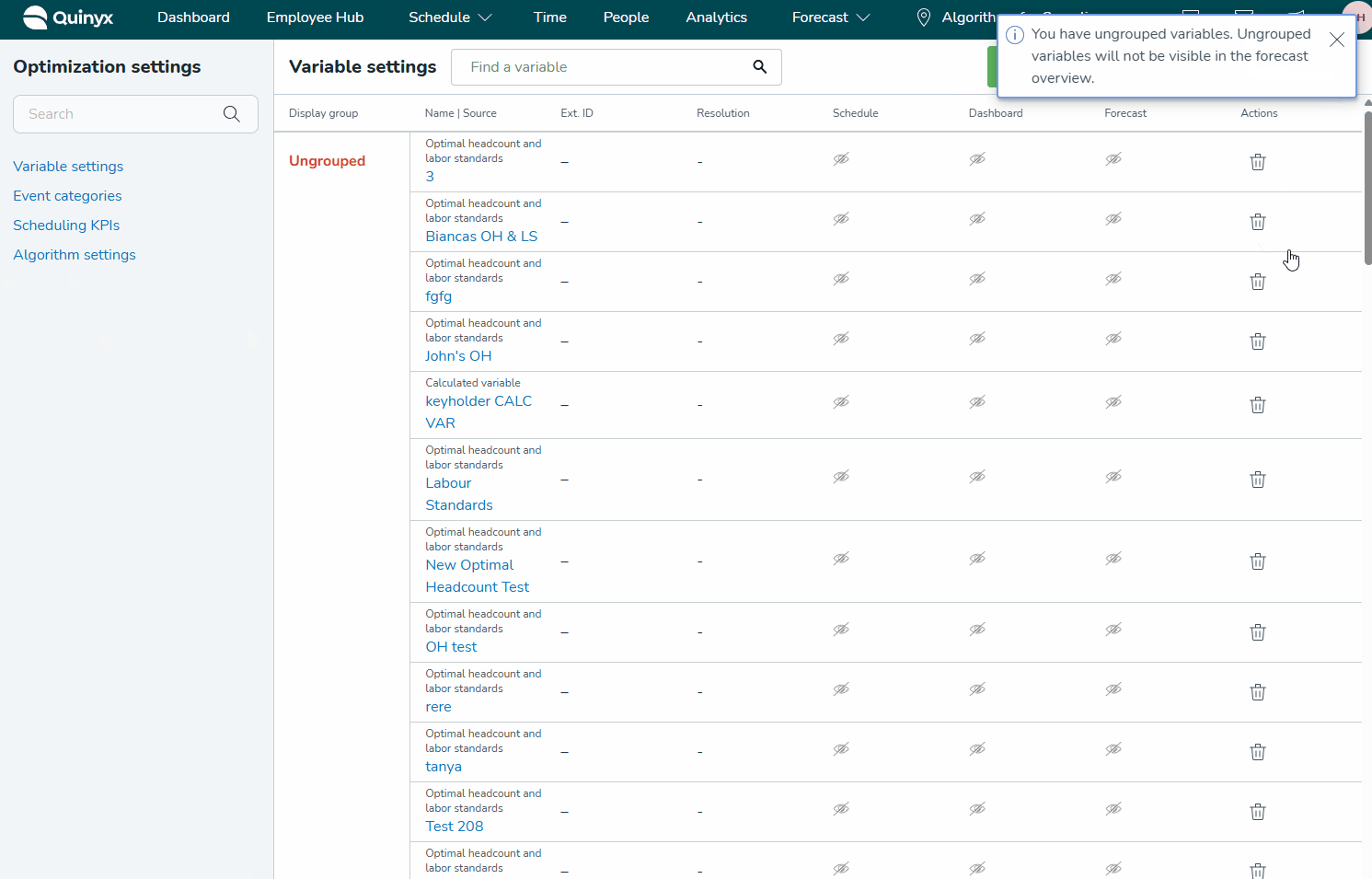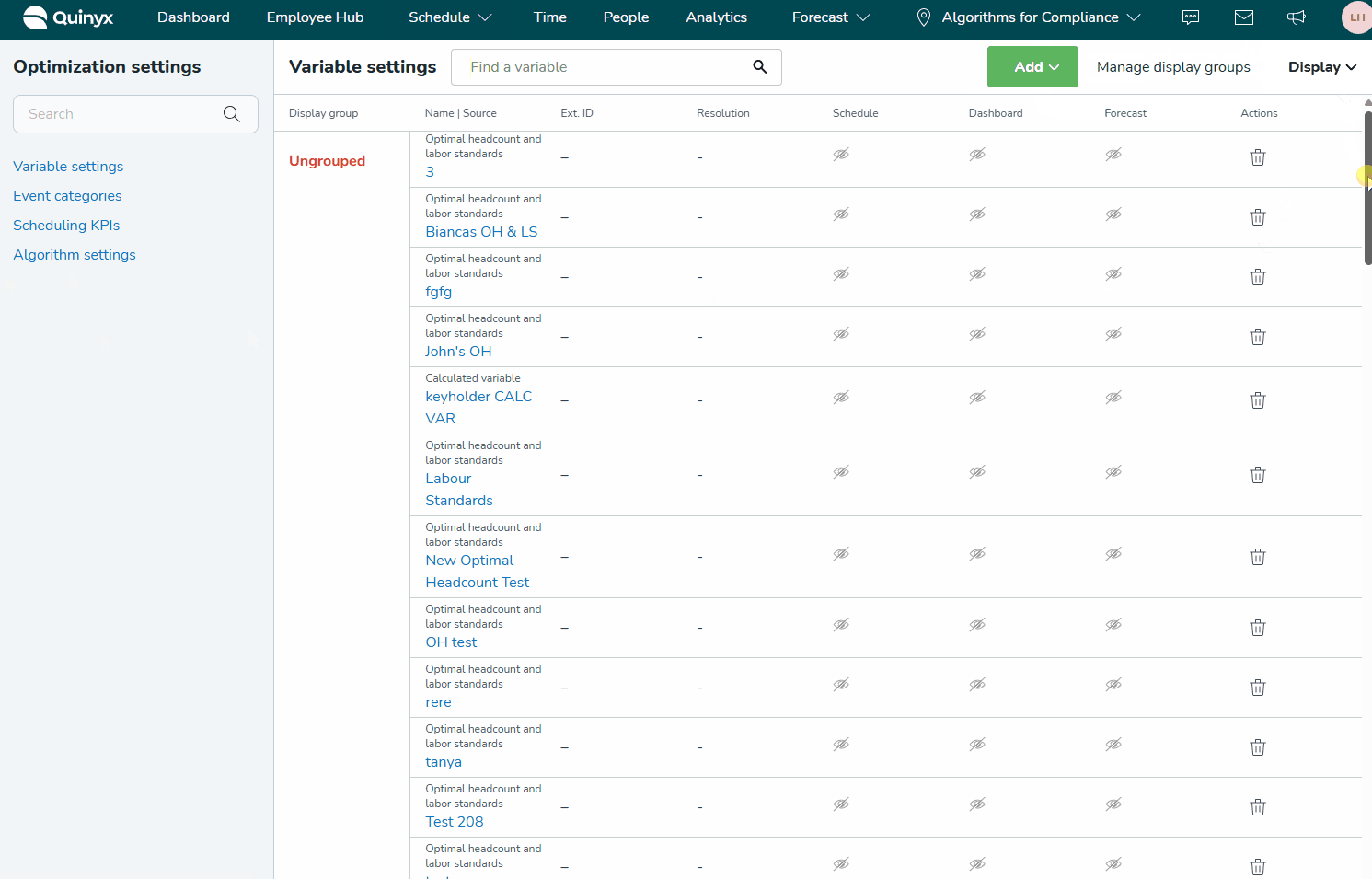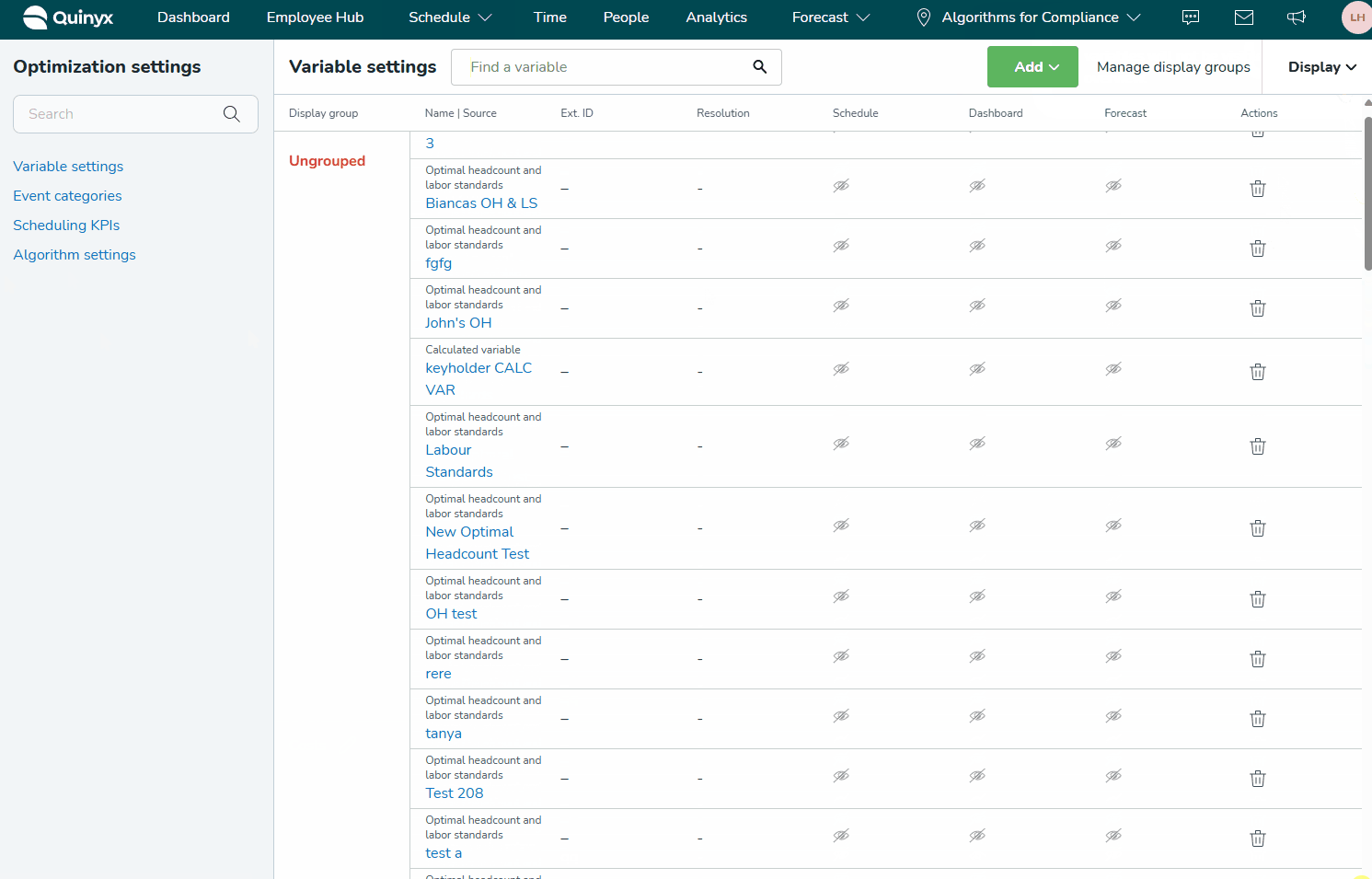
Om du redan har skapat variabler och vill redigera en befintlig, börja skriva namnet i sökrutan. Alla variabelinställningar som innehåller dessa bokstäver kommer att visas.
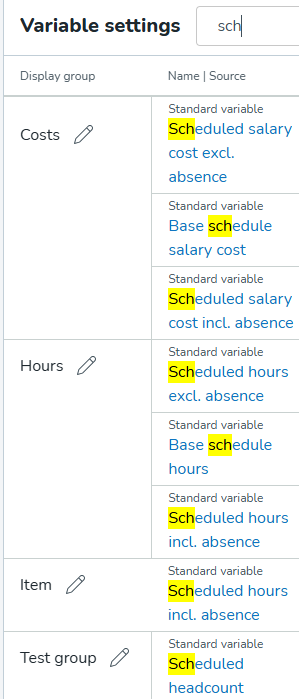
Du kan filtrera inte bara efter variabelnamn utan också efter typ av variabel (t.ex. genom att skriva "optima" kommer alla optimal bemanning-variabler och variabler med namn som innehåller "optima" att visas). För att matcha detta nya sökkriterium har vi också ändrat sökfältets platshållare till "Hitta en variabel" istället för "Sök efter namn."
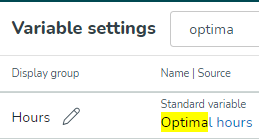
Genom att klicka på Lägg till -knappen högst upp på sidan får du alternativ att lägga till ny Input Data, Forecast Configuration, Calculated Variable eller Optimal Headcount-beräkning.
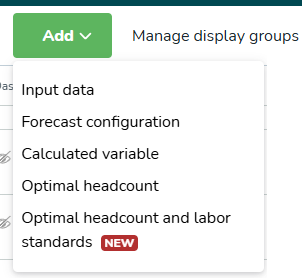
Input data | Externa data som skickas till Quinyx via API:et. Krävs för att generera en prognos. |
Forecast configuration | En konfigurationsuppsättning för att bestämma hur en prognos genereras. Detta måste kopplas till Input Data. Quinyx använder historiska input data för att hjälpa till att generera en prognos för framtiden. |
Calculated variable | En variabel som genereras baserat på beräkningar utförda mellan 2 eller fler variabler. |
Optimal bemanning | Används för att generera en optimal bemanningsberäkning baserad på Statisk och dynamiska regler |
Optimal bemanning och arbetsstandarder | Används för att hjälpa dig att bestämma det optimala antalet personal som behövs för att möta prognostiserad efterfrågan. Läs mer här. |
Input Data
Prognosinputdata är det som driver bemanningsbehoven. Dessa data skickas till Quinyx från ett externt system.
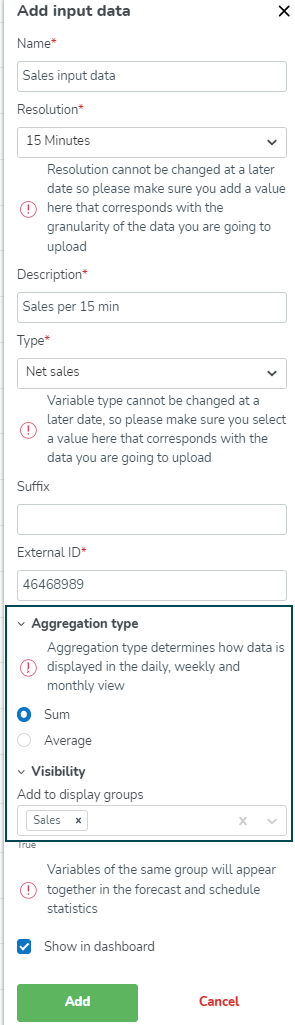
Att välja att lägga till Input Data kommer att visa sidopanelen som kräver följande information.
Namn | Detta är namnet på inputdatan, t.ex. den drivare du vill använda. Till exempel. Nettoförsäljning inkl moms om det kommer att vara de data du kommer att använda kopplade till denna drivare. |
Upplösning (minutnivå) | 5 / 15 / 30 / 60 Minuter: Dessa alternativ låter dig arbeta med mer detaljerade data. Till exempel, att välja 15 Minuter innebär att all tidsrelaterad data (som bemanningsbehov eller skifttäckning) kommer att grupperas och visas i 15-minutersintervall. Upplösning kan inte ändras vid ett senare tillfälle, så se till att du lägger till ett värde här som motsvarar granulariteten i de data du kommer att ladda upp |
Upplösning (daglig nivå) | Utöver befintliga upplösningar (5, 15, 30 och 60 minuter) kan användare nu importera och arbeta med data på daglig nivå. Med daglig upplösning kan du:
Begränsningar i denna version:
Du kan redigera dagliga data direkt inom Prognos-fliken och Schemastatistiken Det dagliga alternativet sammanställer all data till ett värde per dag. Det är bäst att använda när detaljerad timme-för-timme-insikt inte behövs—användbart för hög nivå planering eller rapportering. Viktiga skillnader vid redigering av dagliga data Jämfört med att redigera data med en upplösning på 60 minuter eller mindre har redigering av daglig data följande begränsningar:
|
Beskrivning | Detta är beskrivningen för inmatningsdata för att enkelt kunna identifiera det i inmatningsdatalistan om du har flera inmatningsdata. |
Typ | Detta är typen av inmatningsvariabel och för konfigurationsanvändning och statistisk användning i analys bör den lämpliga typen användas som motsvarar din drivkraft. Till exempel bör Nettoförsäljning inkl moms kopplas till Nettoförsäljning medan Bruttoförsäljning inkl dricks bör vara bruttoförsäljning. Variabeltyp kan inte ändras vid ett senare tillfälle, så se till att du väljer ett värde här som motsvarar de data du kommer att ladda upp |
Suffix | Används inte för närvarande, men kommer att återspegla valuta eller liknande i framtida vyer. |
Externt ID | Detta är det externa ID:t för indata. Detta är en av de saker en integratör skulle behöva för att ladda upp rätt data mot rätt indata i Quinyx. Till exempel, i datalagret för POS-systemet (point of sales) motsvarande nummer för Nettoförsäljning inkl moms. |
Aggregeringstyp | Aggregeringstyp bestämmer hur data visas i den dagliga, veckovisa och månatliga vyn. Välj Summa eller Medelvärde. |
Synlighet | Detta bestämmer vilken/vilka visningsgrupp(er) indata kommer att visas i. För de standardvariabler som automatiskt läggs till i standardvisningsgrupper, såsom Kostnader och Timmar, samt de Optimal Headcount-variabler som läggs till i standardvisningsgruppen Arbetskraft, har Quinyx en liten men betydande komponentindikator i Synlighet inmatning som kommer att representera dessa standardvisningsgrupper. Detta hjälper användare genom att ge information om huruvida en variabel redan är en del av någon standardvisningsgrupp. 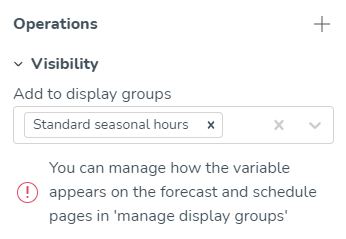 |
Visa i översikt | Definiera om detta ska vara synligt i översiktsvyn. Variabler med lönekostnadsberäkningar kommer inte att visas i översikten. |
Prognoskonfiguration
När du har skapat inmatningsdata kan du skapa en konfiguration för hur framtida data ska prognostiseras.
Du kan göra detta genom att välja Prognoskonfiguration från Lägg till-knappen högst upp på sidan.
Att välja att lägga till Prognoskonfiguration kommer att visa sidopanelen som kräver följande information.
Namn | Detta är namnet på prognosen och hur det kommer att namnges i schemavisningar och andra relevanta vyer. |
Beskrivning | En beskrivning av denna konfiguration för att enkelt kunna identifiera den om många konfigurationer skapas. |
Externt ID | Ett ID för att referera till denna specifika forecast-konfiguration när API:et används. |
Indata | Här väljer du vilken indata som ska användas. Du kan ha flera konfigurationer för samma indata. |
Forecast-formel/Dataalgoritmer | Här definierar du vilka algoritmer som ska användas. För närvarande finns följande:
Quinyx kommer automatiskt att generera en prognos för 90 dagar framåt så länge minst 60 dagars historisk data finns tillgänglig. Läs mer här. |
Aggregeringstyp | Aggregeringstyp bestämmer hur data visas i den dagliga, veckovisa och månatliga vyn. Välj Summa eller Medelvärde. |
Synlighet | Bestämmer vilka visningsgrupper inmatningsdata kommer att visas i. Du kan hantera hur variabeln visas på prognos- och schemasidorna i Hantera visningsgrupper. |
Översikt | Välj om detta ska vara synligt i översiktsvyn. |
Beräknad variabel
En beräknad variabel härleds genom att utföra en beräkning med två andra variabler—dessa kan vara standardvariabler, inmatningsdata eller en blandning av båda.
När du väljer att lägga till en beräknad variabel, öppnas en sidopanel där du behöver ange följande detaljer.
Namn | Namnet på din beräknade variabel och hur den kommer att presenteras i olika vyer. |
Beskrivning | Beskrivningen av din beräknade variabel som kommer att vara synlig i systemet som en referens till den beräknade variabeln. |
Externt ID | Ett ID för att referera till denna specifika variabel när du använder API:et. |
Formel | Här definierar du beräkningen av din variabel. |
Primär inmatning | Den primära inmatningen är den första variabeln du vill använda för din beräkning. Du kan välja från standardvariabler och även från forecastVariable och konfigurationer om du har Neo Forecast aktiverat för din organisation. Detta kommer att vara inmatningsdata före operatorn. |
Anpassad inmatning | Gör det möjligt att lägga till en specifik siffra i den anpassade variabelns ekvation istället för en andra variabel. Observera att ingen beräkning kommer att utföras om data på den primära inmatningen är 0. Dessa beräkningar kommer att utföras med den upplösning som din inmatningsdata är inställd på; 5min, 15min, 30min, 60min. |
Operatör | Operatören bestämmer vad som ska hända med de data du väljer för att skapa en beräknad variabel. De tillgängliga operatörerna är:
|
Sekundär inmatning | Den sekundära inmatningen är den andra variabeln du vill använda för din beräkning. Du kan välja från standardvariabler och även från Forecast-variabler och konfigurationer om du har Neo Forecast aktiverat för din organisation. Detta kommer att vara inmatningsdata efter operatören. |
Synlighet | Bestämmer vilka visningsgrupper inmatningsdata kommer att visas i. |
Visa i översikt | Definiera om detta ska vara synligt i översiktsvyn. För närvarande kommer variabler med lönekostnadsberäkningar inte att visas i översikten. |
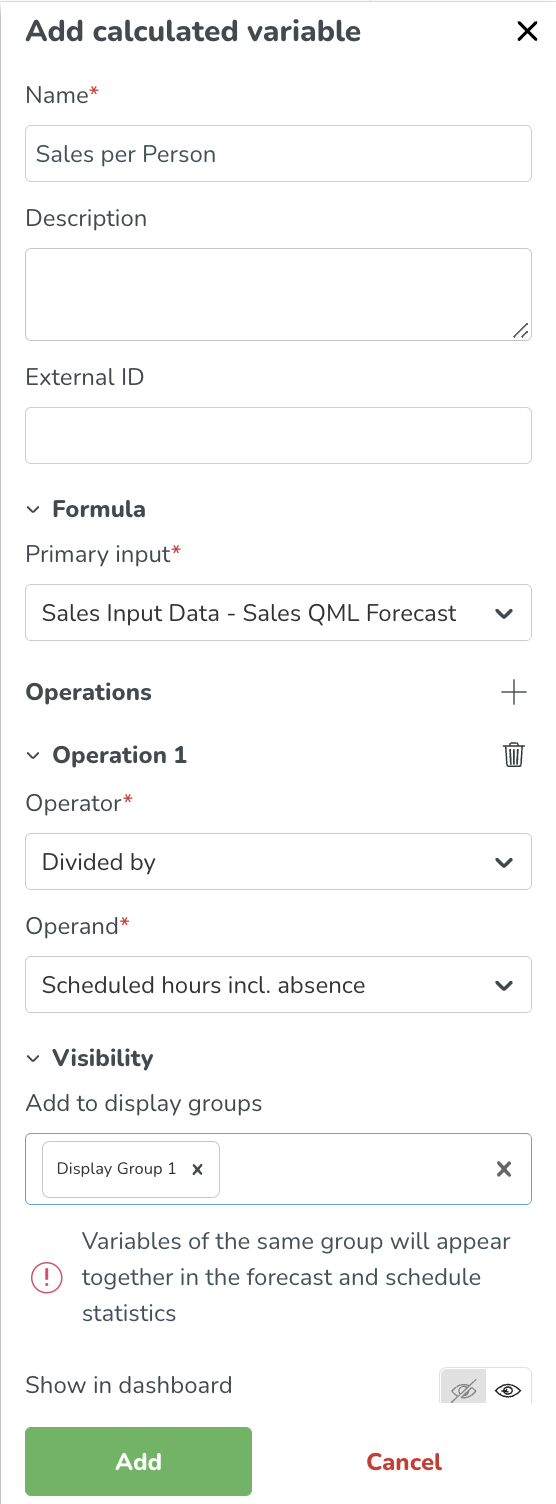
Exempel på en beräknad variabel
Förutsagda försäljningar per schemalagd personaltimme är en vanligt använd KPI inom många branscher.
För att skapa en sådan variabel måste du ha en prognos konfigurerad för att få ett förutsagt försäljningsvärde. Quinyx kan auto-generera denna prognos med hjälp av AI - där din organisation tillhandahåller den faktiska försäljningen.
Läs mer om Algoritmer och prognoser här.
- Primär Input: Förutsagda försäljningar
- Operator: Dividerat med
- Sekundär input: Schemalagda timmar
Exempel på en beräknad variabel med flera operatorer
Vi kommer att använda detta vilda exempel för att visa hur flera operationer beräknas.
Beräkningen kommer att utföras där summorna av varje operation kommer att användas i följande operation, med hjälp av skärmdumpsexemplet nedan, kommer beräkningen att utföras så här:
- Optimala timmar + Schemalagda timmar = x
- x + Arbetade timmar = y
- y + Anpassad input = z
- z / anpassad input = resultat som visas i GUI
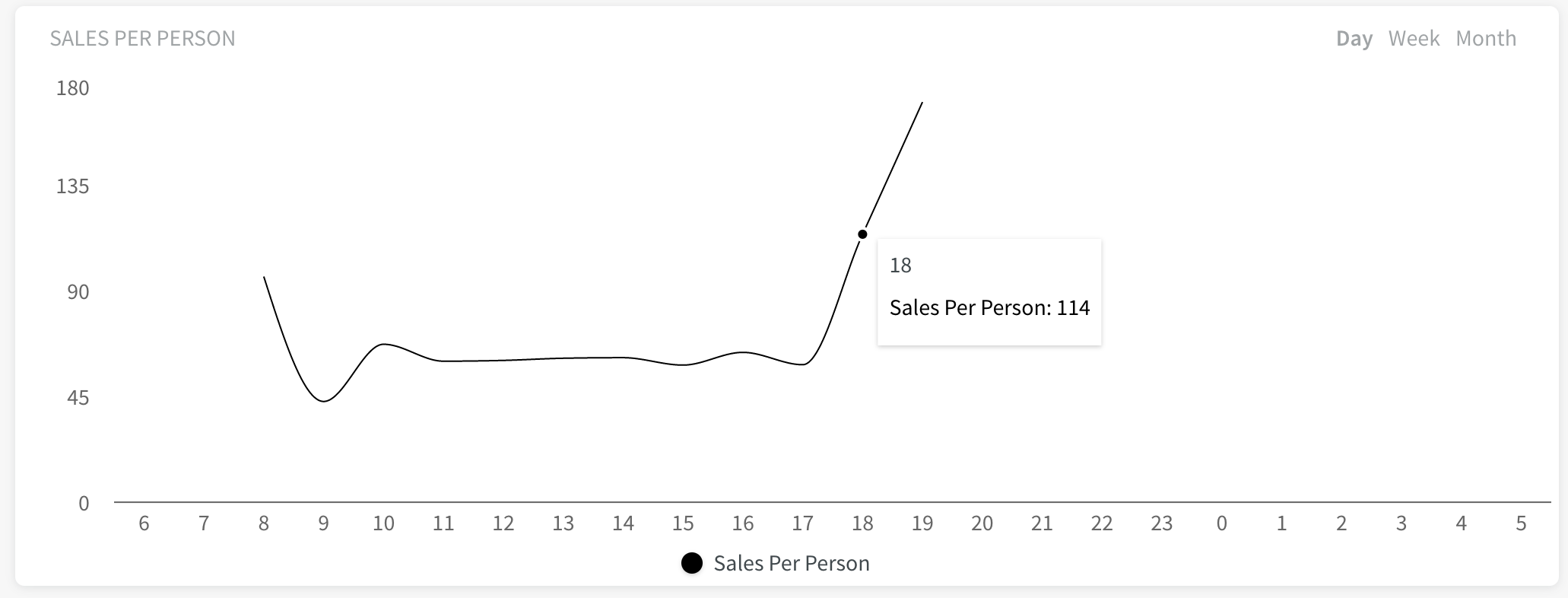
Visa beräknade variabler i Översikten
En beräknad variabel kommer att ha en separat graf i Quinyx översikt. Den kommer fortfarande att ha alternativen för att välja aktuell dag, aktuell vecka och aktuell månad - på samma sätt som de befintliga widgetarna är i översikten idag.
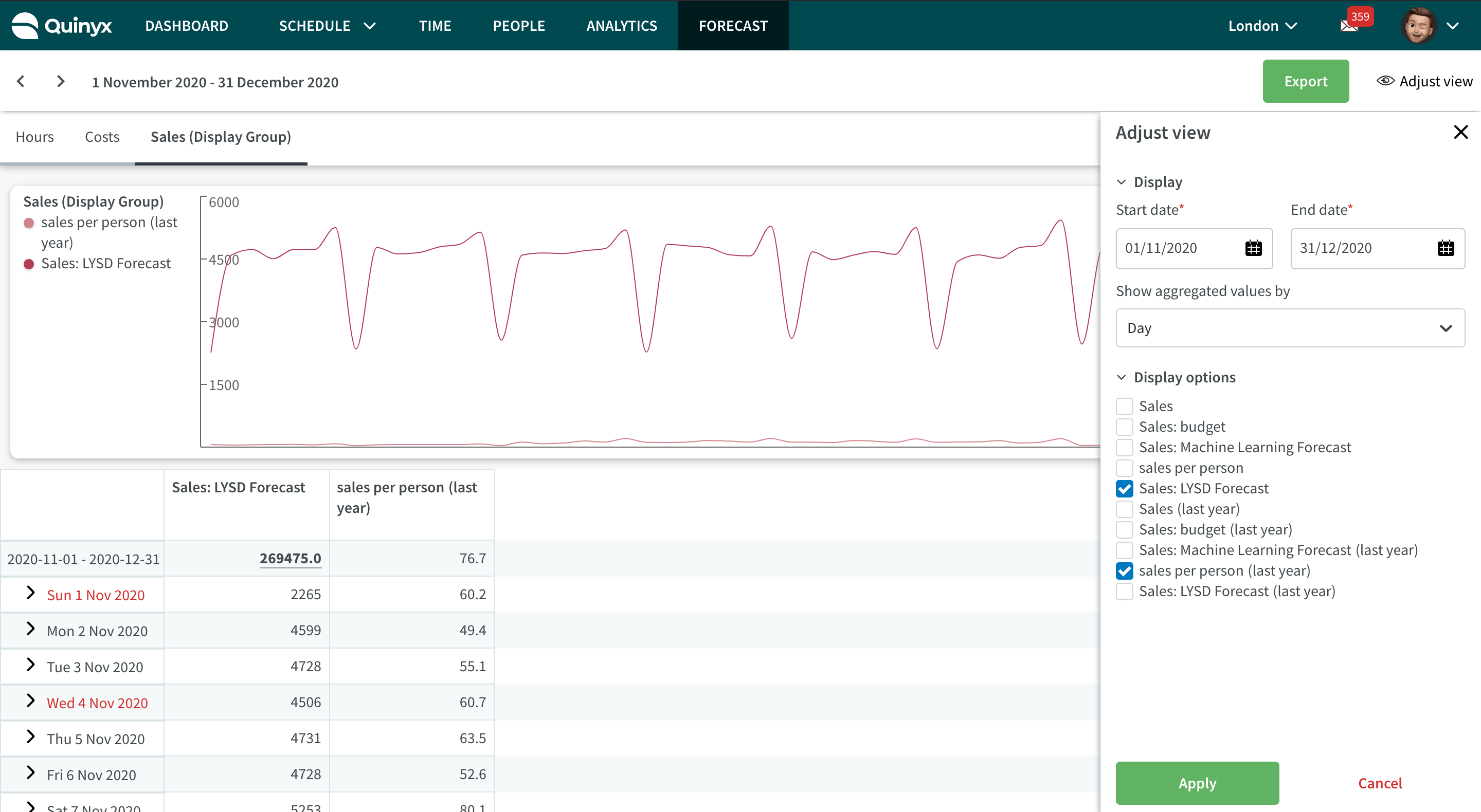
Visa beräknade variabler i Prognosöversikten
Den beräknade variabeln måste läggas till i en visningsgrupp för att visas på Prognosöversikt sidan.
Välja aggregeringstyp på variabler
Aggregeringstypen bestämmer hur data visas i dagliga, veckovisa och månatliga vyer.
Du har möjlighet att välja aggregeringstyp på Input Data, Forecast Configuration, Beräknad variabel eller Optimal bemanning variabler på sidan för Variabelinställningar . När du väljer aggregeringstyp, välj mellan Medelvärde och Summa på varje variabel.
- Summa: När Summa är vald, görs inga ändringar i de nuvarande aggregerade databeräkningarna.
- Medelvärde: När Medelvärde är vald, istället för att summera värdena för att visa den dagliga totalen, visar Quinyx istället det dagliga medelvärdet. Detsamma gäller när man tittar på data i den dagliga, veckovisa eller månatliga vyn. Medelvärdet beräknas genom att ta hänsyn till värdena för varje hink med befintliga data och sedan beräkna medelvärdet baserat på dessa antal hinkar.
För Forecast Configuration-variabler är aggregeringstypen, som standard, samma aggregeringstyp som den som valts för den underliggande Input Data.
Som standard kommer alla befintliga Input Data, Forecast Configuration eller Optimal Headcount-variabler att ha Sum som sin aggregeringstyp, och därför görs inga justeringar av de nuvarande aggregeringsberäkningarna. När du lägger till en ny variabel kommer Input Data-variabler som standard att ha Sum, medan Optimal Headcount -variabler som standard kommer att ha Average som vald aggregeringstyp.
Hur fungerar det?
Quinyx säkerställer att beräkningen i alla fall utförs på varje granularitetsnivå. Exemplen nedan är specifikt för beräknade variabler, inklusive flera variabler av samma eller olika aggregeringstyper. För normal input data, forecast configuration eller optimal bemanning gör Quinyx den generella medelvärdes- eller summaberäkningen. Det är annorlunda för beräknade variabler eftersom du med beräknade variabler faktiskt inte har möjlighet att välja en aggregeringstyp, utan aggregeringarna beräknas baserat på exemplen nedan.
Exempel 1
- Variabel A (aggregeringstyp sum)
- Variabel B (aggregeringstyp average)
- Beräknad variabel C: A/B
- Daglig C = daglig (summa) A / daglig (genomsnitt) B
Beräkningen av Daglig C utförs baserat på de dagliga värdena av de underliggande variablerna.
Exempel 2
- Variabel A (aggregationstyp summa)Variabel B (aggregationstyp summa)
- Variabel C (aggregationstyp summa)Beräknad variabel D: A+B-C
- Daglig D = daglig (summa) A + daglig (summa) B - daglig (summa) C
Beräkningen av Daglig D utförs baserat på de dagliga värdena av de underliggande variablerna.
Exempel 3
- Variabel A (aggregationstyp summa)Beräknad variabel B: A+100 (anpassad inmatning)
- Daglig B = daglig (summa) A + 100
Beräkningen av Daglig B lägger till den anpassade inmatningen som definierats i de beräknade variablerna, inte som en summa av tillägget av den anpassade inmatningen på den lägsta granulariteten.
Optimal bemanning variabler
Kunder som använder statiska och dynamiska regler i kombination med sina prognostiserade indata för att generera en optimal bemanning kommer att behöva skapa en Optimal bemanning variabel som är kopplad till dessa regler.
Navigera till Lägg till > Optimal bemanning.
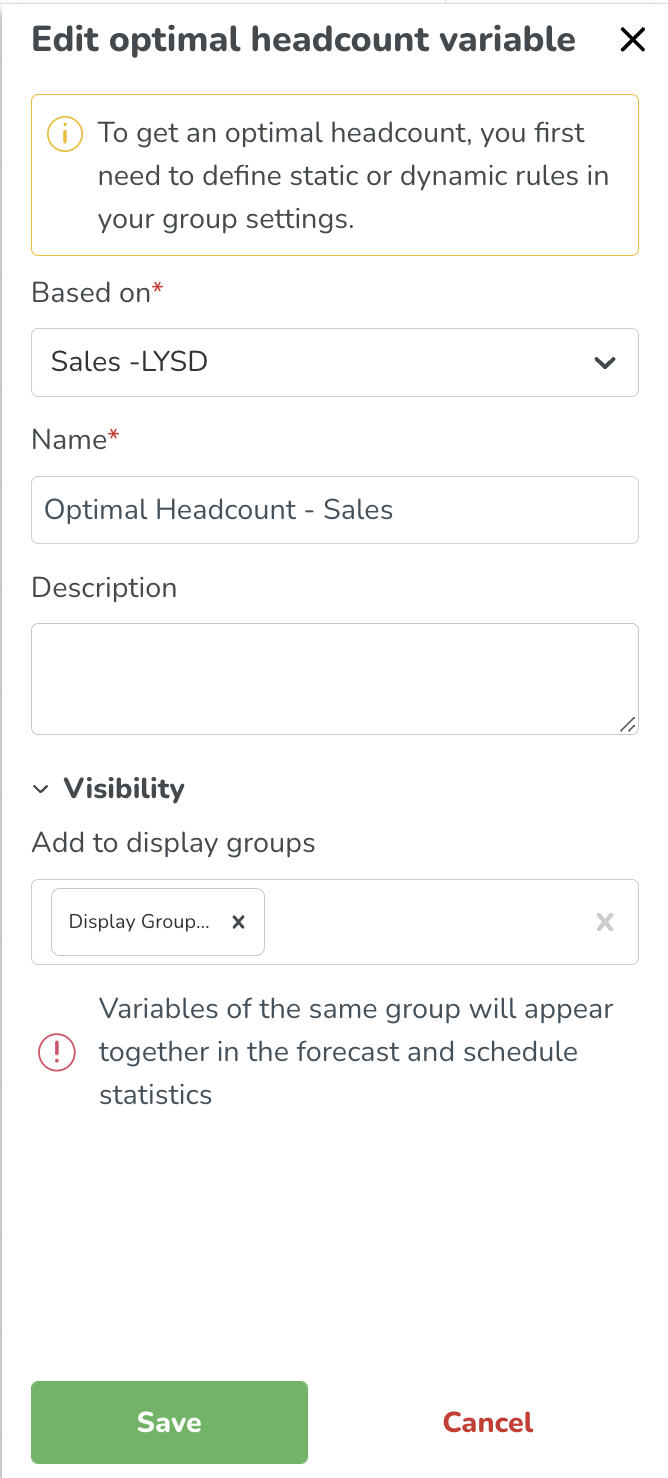
Baserat på | Vilken uppsättning regler ska beräkningen av optimal bemanning baseras på - här kommer du automatiskt att se alla prognoskonfigurationer som har skapats och har statiska eller dynamiska regler kopplade till dem. I framtiden kommer vi att lägga till stöd för endast statiska regler. När variabeln har skapats kommer beräkningen att göras automatiskt. |
Namn | Vad du vill att din Optimal Headcount Variable ska kallas. |
Beskrivning | En beskrivning av denna variabel för att enkelt kunna identifiera den. |
Aggregeringstyp | Aggregeringstyp bestämmer hur data visas i den dagliga, veckovisa och månatliga vyn. Välj Summa eller Medelvärde. |
Synlighet | Bestämmer vilka visningsgrupper inmatningsdata kommer att visas i. Du kan hantera hur variabeln visas på prognos- och schemasidorna i Hantera visningsgrupper. |
Optimal headcount variabeln kommer nu att visas i din variabellista inom den visningsgrupp du har tilldelat den, eller som ogrupperad om du ännu inte har tilldelat den en.

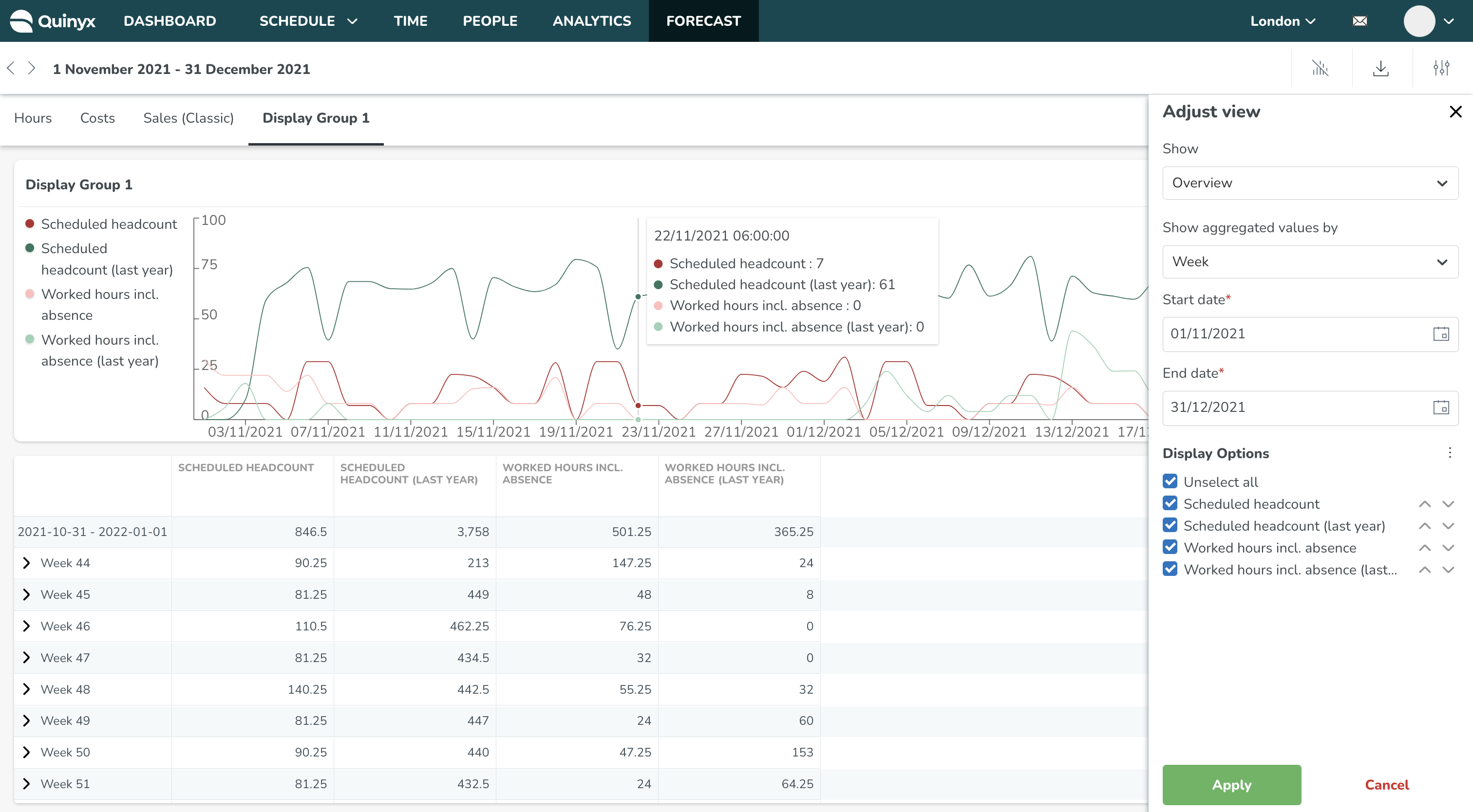
Visningsgrupper
Visningsgrupper är ett sätt att gruppera indata, standardvariabler, optimal bemanning-variabler och beräknade variabler i en enda grupp så att de visas tillsammans på grafer och tabeller inuti Prognosöversikt och inom Schema Statistiken.
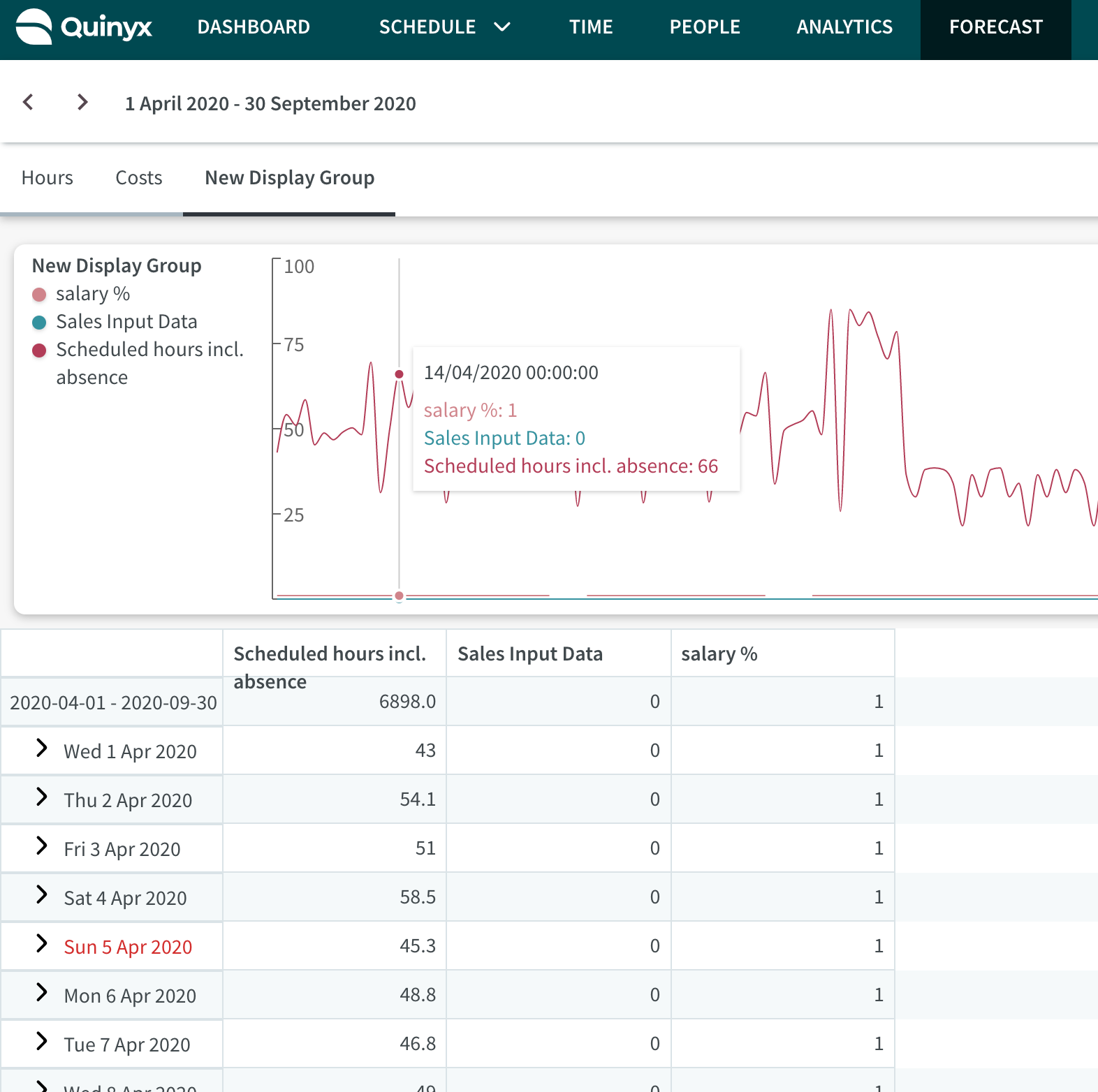
Som standard kommer Quinyx att ha två visningsgrupper: Kostnader och Timmar. Vi har också en tredje standardvisningsgrupp som kallas Arbetskraft, som automatiskt kommer att läggas till om du skapar en optimal bemanning med hjälp av Optimal bemanning och arbetsstandarder - NYTT -funktionen. Du kan fortfarande hantera variablerna inom dessa grupper. Läs vidare för att lära dig hur detta görs.
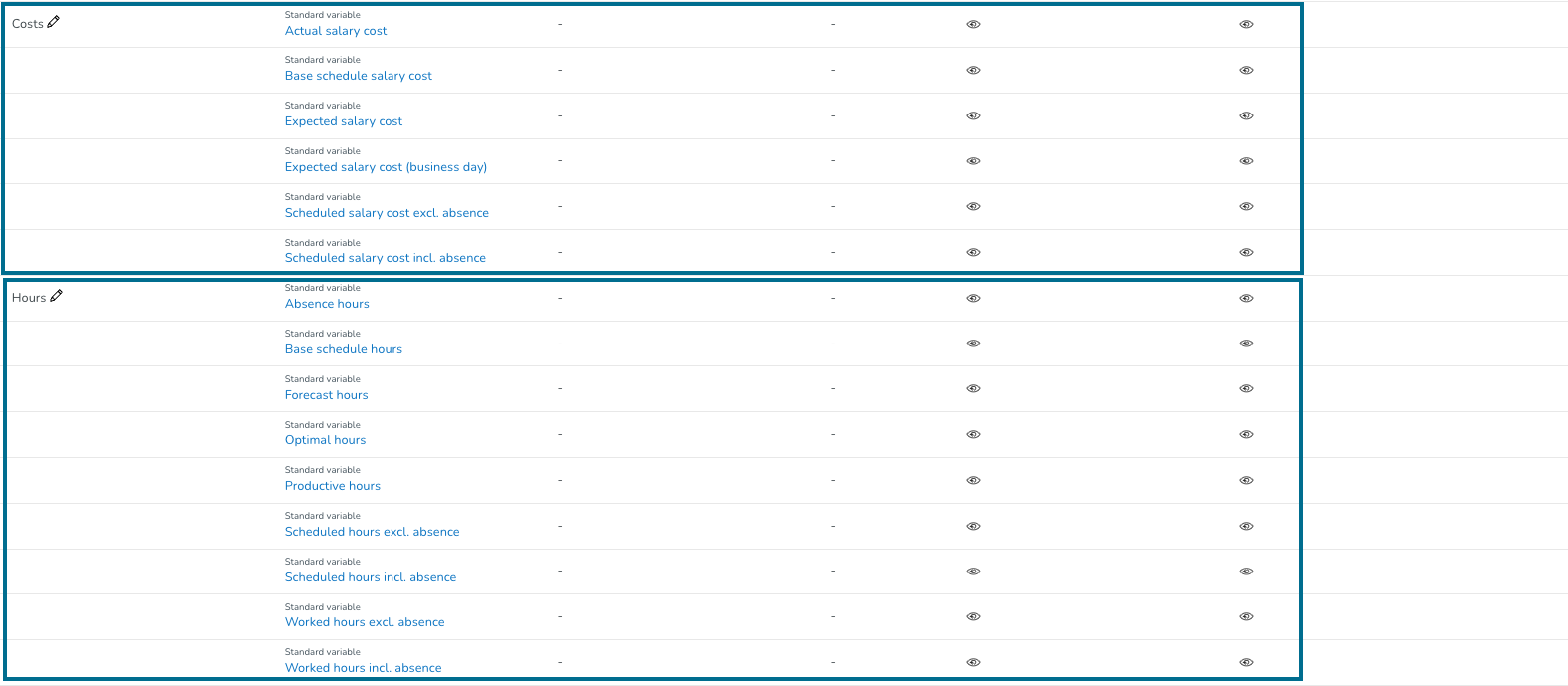
För att skapa en ny visningsgrupp, klicka på Hantera visningsgrupper högst upp på sidan.
Detta kommer att öppna ett fönster som visar alla nuvarande visningsgrupper. Klicka på + för att skapa en ny grupp.
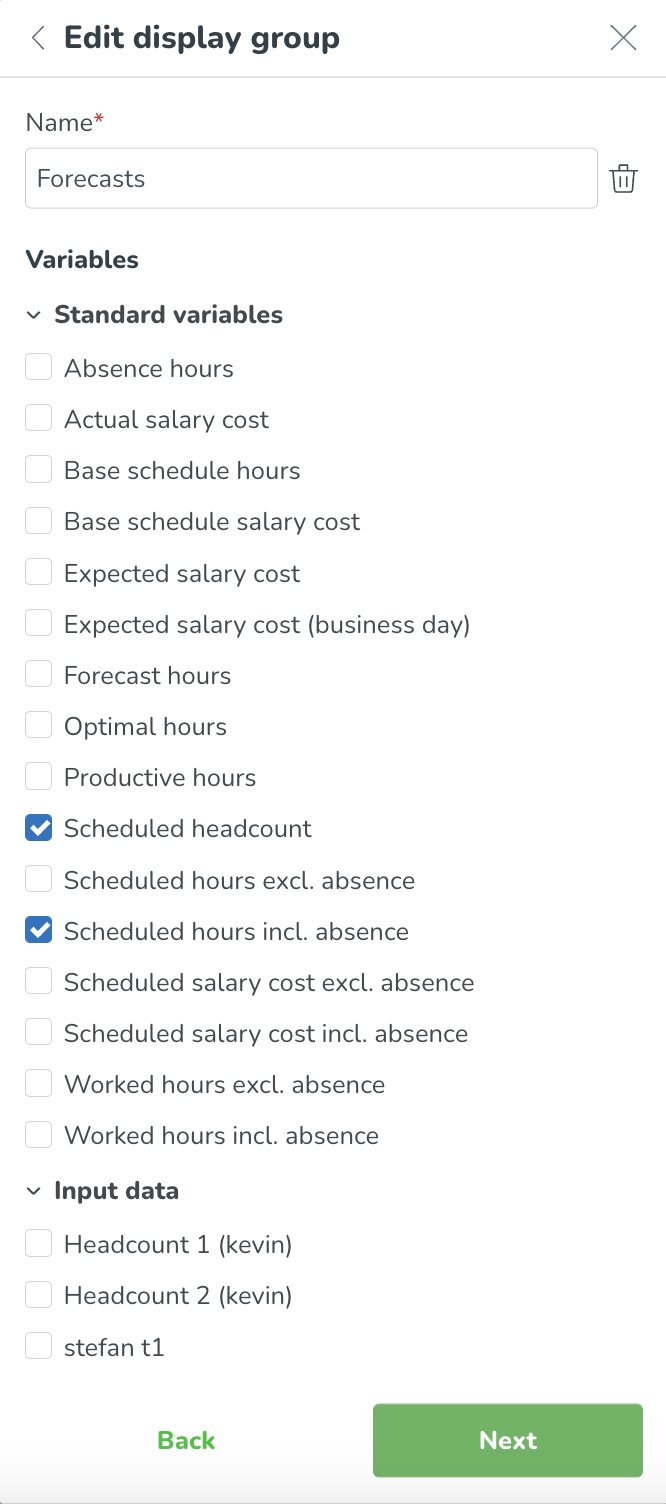
Ange ditt nya visningsgruppnamn och välj vilka variabler du vill visa tillsammans i denna grupp och klicka på Nästa.
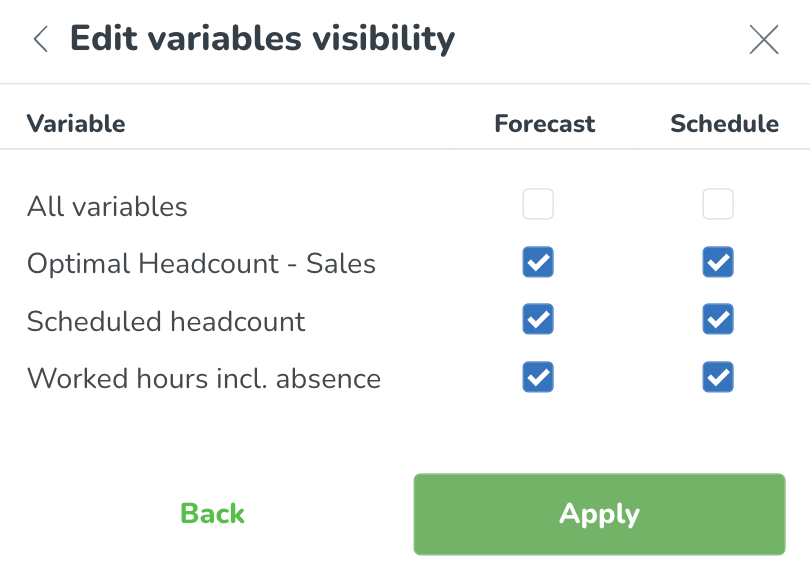
På följande sida kan du välja vilka variabler du vill ska vara synliga i schema-statistiken och prognos fliken. Klicka på Verkställ för att spara dina ändringar.
Din nya grupp har skapats och kommer nu att visas i listan över hanterbara visningsgrupper.

Du kan redigera namnet genom att klicka på Hantera visningsgrupper > sedan pennan, eller så kan du ta bort visningsgruppen genom att klicka på papperskorgen.
Genom att klicka på pennaikonen kan du redigera de variabler du vill visa inom visningsgruppen. Kom ihåg att de variabler du väljer här kommer att visas tillsammans på grafer och tabeller.
Du kan nu navigera till Schema eller Prognos flikarna för att se och hantera variablerna inom visningsgrupperna.
Visningsgrupper i Schema-statistiken

Visningsgrupper i Prognos